Lecture 01 2022/01/18
- Why study OS
- To learn the language of systems: abstraction
- To understand issues of system design
- To under stand how computers work
- What is OS
- An OS is a program that acts as an intermediary between a user and the computer hardware
- Goals
- Execute user programs and maker solving user problems easier
- Make the computer system convenient to user
- Use the computer hardware in an efficient manner
- Computer system components
- Hardware: CPU, memory, I/O devices
- OS
- Application programs
- Users: people, machines, other computers
- What the OS does
- OS is a resource allocator: manage all resources
- OS is a control program: control execution of programs
- Resource Management
- Resource abstraction (top-down view)
- Abstract from functionality of hardware, to achieve ease of use and device independence
- Resource sharing (bottom-up view)
- manage contention for resources
- The one program running at all times on a computer is the kernel, everything else is either a system program or an application program
- Resource abstraction (top-down view)
- Key OS concepts
- Processes = programs + state
- Program in execution, also include some state information
- Context switch: change control from one process to another
- Concurrency
- Used for performance
- Programs do not corrupt, programs can achieve goals (fairness, performance,...), do not deadlock
- Memory management
- Each process has access to entire machine
- Abstraction + sharing
- Device management
- Each process has access to all devices
- Abstraction + sharing
- Processes = programs + state
- Overview of machine organization
- CPU: a processor for interpreting and executing programs
- Memory: for storing data and programs
- Controller: mechanism for transferring data from/to outside world, there is a controller for each device
- Buss: set of wires, move data and instructions within units of the
machine
- Buss should contains both data and address
- Primary movement on buss
- CPU
- CPU
- Memory
- CPU
Lecture 02 2022/01/20
- CPU
- CPU = ALU + Control Unit
- ALU (arithmetic logic unit): performs computations
- Control unit: interprets program instructions
- CPU fetches, decodes and executes instructions on the correct data
- Control unit makes sure the correct data is where is needs to be
- ALU: stores and performs operations on data
- CPU understands only assembly language
- ALU
- ALU = Registers + Function unit
- Registers: storage units for data (addresses, PC, operands, ...)
- Registers are fast and expensive
- Cetegories:
- GPR (general purpose registers): set directly by the software, stores data
- SR (status register): set as a side-effect of software
- The amount of registers is the power to 2, typically 32-64
- Each register holds a word, the size of a word is the amount that could be stored in a register, it's also the amount of data that could be transferred by one bus at a time
- Function unit: evaluate arithmetic and logic units
- Operations in FU can affect bits in the SR
- FU is controlled by signals from the CU, so it knows which operation to perform
- Registers and units are connected through the CPU bus, timing of the movement of data is controlled by CPU clock
- Generate assembly language
- Higher level languages are converted to assembly language using a compiler
- Movement of data
- Memory
LOAD - Register
STORE - Memory
READ - Disk
WRITE
- Memory
- System call: request to OS to perform service, change from user mode to kernel mode
- Source code
- Control unit
- PC (program counter): a register for the CPU, stores the address where the program is stored in memory
- IR (instruction register): a register for the CPU, holds instruction currently being executed or decoded
- CU performs the "Fetch-Decode-Execute" cycle after instructions are
loaded into memory by the loader
- Get the instruction whose address is at PC, store the instruction in IR
- Decode instruction in IR to identify operation type and inputs
- Execute instructions with ALU
- Increment PC (by 4 in the 32-bit configuration)and go back to fetch another instruction
- This cycle is controlled by the halt flag. THe halt flag is the
first bit in the SR, when it is set to CLEAR, the bit is set to 0, and
the program runs. When the last line of the program is executed, IR has
the halt instruction, and the halt flag is set to 1, then the program
stops
1
2
3
4
5
6
7PC = <start address>
IR = M[PC]
haltflag = CLEAR
while (haltflag is CLEAR)
Execute (IR)
Increment (PC)
IR = M[PC]
- Booting
- OS is not in ROM, but on the disk
- OS is large
- OS needs to be changed when needed (update)
- BIOS (non-volatile firmware on flash memory of motherboards): part of hardware, initializes hardware and runs the bootstrap loader
- Bootstrap loader: part of software, resides in ROM, it loads OS into memory
- BL algorithm
1
2
3
4
5
6
7R3 := 0 // Size of transferred data
R2 := SIZE_OR_TARGET // Size of OS
while R3 < R2 do
R1 := disk[FIXED_DISK_ADD + R3]
M[FIXED_MEM_ADD +R3] := R1
R3 : R3 + 4
goto FIXED_MEM_ADD
- OS is not in ROM, but on the disk
Lecture 03 2022/01/25
- Assumption and notation
- Assumptions
- 16 GPR (R1, ..., R16)
- 16 SR (S1, ..., S16)
- Instruction size: 4 bytes
- Notation
M[x]: contents of memory at address xD[x]: contents of disk at address xRi: contents of GPR Ri- PC: program counter
<-: assignment
- Assumptions
- Load: transfer data from memory to cpu
- Direct addressing
- Syntax:
LOAD Ri, Addr - Meaning:
Ri <- M[Addr] - Example:
LOAD R1, 3000
- Syntax:
- Immediate operand
- Syntax:
LOAD Ri, =Num - Meaning:
Ri <- Num - Example:
Load R2, =100
- Syntax:
- Index addressing
- Syntax:
LOAD Ri, [Addr, Rj] - Meaning:
Ri <- M[Addr + Rj] - Example:
Load R3, [3000, R4]
- Syntax:
- Indirect addressing
- Syntax:
LOAD Ri, @ Addr - Meaning:
Ri <- M[M[Addr]] - Example:
Load R5, @ 3000
- Syntax:
- Relative Addressing
- Syntax:
LOAD Ri, $Num - Meaning:
Ri <- M[PC + Num] - Example:
LOAD R6, $100,LOAD R7 $R8
- Syntax:
- Direct addressing
- Store: transfer data from cpu to memory
- Direct addressing
- Syntax:
STORE Ri, Addr - Meaning:
M[Addr] <- Ri - Example:
STORE R1, 3000
- Syntax:
- Index addressing
- Syntax:
STORE Ri, [Addr, Rj] - Meaning:
M[Addr + Rj] <- Ri - Example:
STORE R2, [3000, R3]
- Syntax:
- Relative addressing
- Syntax:
STORE Ri, $Num, - Meaning:
M[PC + Num] <- Ri - Example:
STORE R4, $100,STORE R5, $R6
- Syntax:
- Direct addressing
- Arithmetic operations
- ADD
- Syntax:
Add Ri, Rj - Meaning:
Ri <-Ri + Rj
- Syntax:
- SUB
- Syntax:
SUB Ri, Rj - Meaning:
Ri <- Ri - Rj
- Syntax:
- MUL
- Syntax:
MUL Ri, Rj - Meaning:
Ri <- Ri * Rj
- Syntax:
- DIV
- Syntax:
DIV Ri, Rj - Meaning:
Ri <- Ri / Rj(integer division),Rj <- Ri % Rj - Example
1
2
3LOAD R1, = 11
LOAD R2, = 4
DIV R1, R2 // R1 = 2, R2 = 3
- Syntax:
- INC
- Syntax:
INC Ri - Meaning:
Ri <- Ri + 1
- Syntax:
- ADD
- Labels
- Syntax:
LOOP: instruction - This is the same meaning as the instruction alone, but it is used with branch instructions to construct a loop
- If the "LOOP" label appears at memory address 3000, then throughout the code, "LOOP" is equivalent to 3000
- Syntax:
- SKIP
- Syntax:
SKIP - Meaning: time delay, cpu pauses for about 300 cpu cycles
- Syntax:
- Branch
- BR
- Syntax:
BR label - Meaning: branch to label
- Syntax:
- BLT/BGT/BLEQ/BGEQ
- Syntax:
BLT Ri, Rj, label - Meaning: branch to label if Ri < Rj
- Syntax:
- BR
- READ: transfer data from hardware to cpu
- Direct addressing
- Syntax:
READ Ri, DiskAddr - Meaning:
Ri <-D[DiskAddr] - Example:
READ R1, 30000
- Syntax:
- Index addressing
- Syntax:
READ Ri, [DiskAddr, Rj] - Meaning:
Ri <- D[DiskAddr + Rj] - Example:
Read R2, [30000, R3]
- Syntax:
- Direct addressing
- WRITE: transfer data from cpu to hardware
- Direct addressing
- Syntax:
WRITE Ri, DiskAddr - Meaning:
D[DiskAddr] <- Ri - Example:
WRITE R1, 30000
- Syntax:
- Index addressing
- Syntax:
WRITE Ri, [DiskAddr, Rj] - Meaning:
D[DiskAddr + Rj] <- Ri - Example:
WRITE R2, [30000, R3]
- Syntax:
- Direct addressing
- HALT
- Syntax:
HALT - Meaning:
haltflag <- 1
- Syntax:
- Exercise
- Given
1
2
3
4
5
6
7
8
9
10
11
12at x READ R1, d1 // b
at x+ 4 READ R2, d2 // p
at x + 8 LOAD R3, =1 // i
at x + 12 LOAD R4, =4 // step
at x + 16 LOAD R5, =1 // res
at x + 20 LOAD R6, = 972 // initial offset
at x + 24 LOOP: MUL R5, R1 // res *= b
at x + 28 STORE R5, $R6 // M[offset] = res
at x + 32 Add R6, R4 // offset += step
at x + 36 INC R3 // i+= 1
at x + 40 BLEQ R3, R2, LOOP // while i <= p
at x + 44 HALT // stop
- Given
- Binary representation
- Convert decimal number to binary form:
- Convert decimal number to binary form:
- Memory
- Memory is divided into cells, typical cell size is 1 byte = 8 bits, each cell has an address
- If the computer is m-bit (the length of cpu register is m), then it
can be mapped to
- There are three registers used to handle data transaction between
cpu and memory
- MAR (memory address register): stores memory address from which data will be fetched or to which data will be stored
- MDR (memory data register): stores data being transferred to and from memory address specified by MAR, it can both load data and store data
- CMD (command register): indicates whether the command is load or store
- Example
1
2
3
4
5
6
7
8
9STORE R1, 3000
MDR <- R1
MAR <- 3000
CMD <- WRITE
LOAD R1, 3000
MDR <- R1
MAR <- 3000
CMD <- READ
- Memory categories
- Main memory: CPU can access directly, this is volatile (when the computer is shut down, the data in the main memory is lost)
- Secondary storage: extension of main memory that provides large, nonvolatile storage capacity
- Hardware hierarchy

- Devices and controllers
- I/O devices: keyboard, mouse, monitor, printer, disk, ...
- Device controllers: hardware interface between device and bus, handlers the I/O signals of CPU, device controllers are physical chips, but device drivers are softwares
- Interrupts
- One I/O interrupt example:
- CPU issues a read request to the device through the device driver
- Device driver signals the device controller to get the data while CPU does other work
- Device will interrupt the CPU when ready to transfer the data
- CPU transfers control to the device
- Device transfers the data to CPU
- A trap/exception is a software-generated interrupt caused either by an error or a user request
- How interrupt notifies CPU
- Method 1: interrupt request flag(IR flag)
- One status register directly wired to the device controller's DONE flag, when the DONE flag is set to be true, the CPU is notified through the IR flag
- For this approach, if there are multiple devices in the computer, cpu cannot know which one sends the interrupt request, so it needs to ask each device in turn (called polling procedure), which slows interrupt processing
- Method 2: interrupt vectors
- If the length of the interrupt vectors is
- The interrupt vector is part of the hardware
- If the length of the interrupt vectors is
- Method 1: interrupt request flag(IR flag)
- Fetch-decode-execute with interrupt involved
1
2
3
4
5
6
7
8
9
10PC = <start address>
IR = M[PC]
haltflag = CLEAR
while (haltflag is CLEAR)
Execute (IR)
Increment (PC)
if (interrupt request)
M[0] <- PC // reserved to store PC
PC <- M[1]/ PC <- M[i] // if IR flag is used, use M[1] is the interrupt handler, if interrupt vector is used, use M[i] as the interrupt handler for ith device
IR = M[PC]
- One I/O interrupt example:
Lecture 05 2022/02/01
- Respond to interrupt
- Procedures
- Save processor state (PC, registers, ...)
- Identify interrupting device and sets PC to address the appropriate device handler
- Device handler performs data transfer from device controller registers to cpu
- Interrupt during interrupt
- Problem 1: the later interrupt overwrites M[0]
- PC = 108 => 1st interrupt => M[0] <- 108, PC <- M[1]
- 2nd interrupt => M[0] <- M[1], PC <- M[2]
- When the 2nd interrupt id done, PC <- M[1], but we lost the first PC <- 108
- Solution: reserve additional memory for PC values, so different interrupt store their respective PC at different memory addresses
- Problem 2: wrong timing leads to unhandled interrupts
- Two interrupt arrives almost at the same time, then M[0] is set to the PC for the 2nd interrupt, then the 1st interrupt is unhandled
- Solution: set an interrupt disable other interrupts until cpu recognizes which devices are interrupting
- Problem 1: the later interrupt overwrites M[0]
- Procedures
- Kernel vs User mode
- OS and users share the hardware and software resources of a computer system
- OS should be able to protect the integrity of the computer, so OS needs to distinguish between kernel mode and user mode
- Switch between 2 modes of operation: a mode bit on one register:
- Uer mode: execution in user role, limited instructions, no privileged instructions
- Kernel mode: execution in OS role, privileged instructions are allowed, (interrupt, trap, fault are handled in this mode)
- All I/O instructions are privileged, so there is switch between user mode and kernel mode
- To prevent infinite loop/ process hogging resources, there is also transition from user to kernel mode, a timer is involved
- When the program logic is focused, the user does not need to care about which call triggers the switch between modes, but if efficiency is an issue, calls without switch between modes are preferred
- Processes
- Processes are abstraction of the CPU and the main memory
- Process is an abstraction of the cpu
- It gives an illusion of a uni-programming environment, every process acts as if it has exclusive access to cpu and memory (in reality, cpu is time-sliced, memory is space-sliced)
- Multiple processes increase cpu utilization
- Multiple processes reduce latency
- A thread is a lightweight process, it's an abstraction of the cpu, but not of the main memory
- Threads are mostly cooperative, processes are mostly independent
- A process is more than the program code, it consists of code section, data section, stack, registers(include the PC)
Lecture 06 2022/02/04
- Process state
- Processes are not always running, they have different states
- State:
- New: process is being created
- Running: instructions are being executed
- Waiting: process is waiting for some event to occur
- Ready: process is waiting to be assigned the cpu
- Terminated: process has finished execution
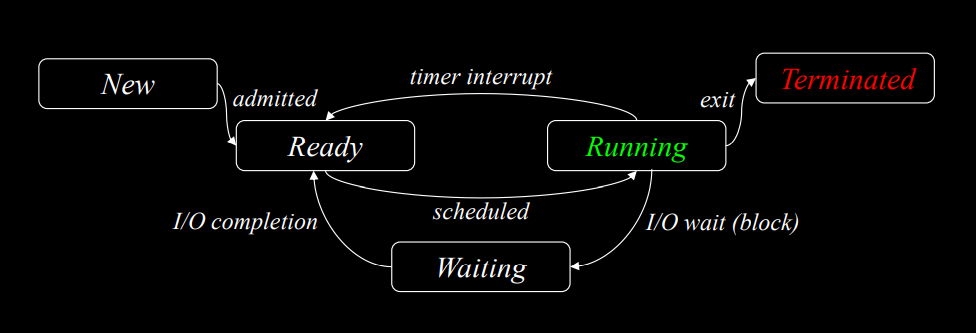
- Process control block
- Each process is represented in the os by a process control block, also called a task control block. It contains many information associated with a specific process
- Information
- Process state: new, running, etc.
- Process id
- PC
- Registers
- Memory limits
- Other information: list of opened files, etc.
- Context switch:
- Process with access to cpu switched out (due to interrupt or system call), with state copied to pcb, another ready process switched in, also with state copied from pcb
- There is a queue managing processes, if a process is switched out, then it's enqueued, then another process is dequeued from the scheduling queue based on some criterion and switched in
- Pure overhead: during context switching, no useful work is done in cpu
- Process scheduling
- Multiprogramming goal: maximize cpu utilization and enable users
interact with their running programs. This is achieved by process
scheduler, it selects the progress for program execution on the cpu
- Scheduler
- Long term scheduler (job selector): moves process from disk to main
memory
- Select which processes should be moved into ready queue
- Control degree of multiprogramming (# of processes in memory)
- Invoked infrequently, can be slow
- Need to make a mix of I/O bound processes (spend more time doing I/O)and cpu bound processes (spends more time doing computation)
- Short term scheduler: selects one process from memory and allocate
the cpu to it
- Similar to interrupt handler
- Select processes from ready queue
- Invoked frequently, should be fast
- Long term scheduler (job selector): moves process from disk to main
memory
- Multiprogramming goal: maximize cpu utilization and enable users
interact with their running programs. This is achieved by process
scheduler, it selects the progress for program execution on the cpu
- Process and memory
- Process address space contains text segment, data segment and stack segment
- Abstraction
- The process has access to whole memory, in reality memory is partitioned amongst processes
- Memory is contiguous, in reality memory consists of non-contiguous chunks (if a process is terminated, its memory is free, then there are empty chunks)
- Abstraction 1: process has exclusive access to all memory that it
can address
- Exclusivity: each process is assigned a base register and limit register defining its address space, so the memory space is [base register, base register + limit register]
- Access to entire address space: in reality, the entire memory space occupied by processes can be larger than physical memory using the virtual memory technique
- Abstraction 2: a process's address space is contiguous
- Store process's address space as non-contiguous set of contiguous chunks
- Process creation
- Process creation
- Parent process creates child processes, forming a tree of processes
- Child process possibilities
- Resource sharing: child process shares all sources from parent process, subset of parents's, none resource with the parent
- Execution: parent executes concurrently with children processes, parent process waits until all children processes are terminated
- Address space: child is a duplicate of parent, child has specified new program loaded
- Process creation in UNIX:
fork(),execv(path, argv)fork()- Creates new child processes by creating a copy of executing process within new address space, return 0 to newly created child process and return the pid of the child process to the parent
- Shared memory are shared between parent and child processes, stack and heap are copied between parent and child processes
execv(path, argv): replaces the process memory space with respect to specified program in path and arguments argvExample 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int vaule = 5;
int main() {
pid_t pid;
pid = fork();
if (pid == 0) {
/*Only child executes*/
value += 15;
return 0;
} else if (pid > 0) {
/*Only parent executes*/
wait(NULL);
/*This should print 5*/
printf("Parent: value = %d\n", value);
return 0;
}
}Example 2
1
2
3
4
5int main() {
fork();
fork(); /*Both child and parent execute this*/
fork(); /*Both child and parent execute this*/
}
- Process creation
Lecture 07 2022/02/07
- Processes
- The process id for child is larger thant that of the parent process, but may not be consecutive
- They have separate copies of data and separate PC
- Global variables are the same after copy, but if one processes changes it, other processes cannot notice the change
- Process termination
- Exit: When a process executes last statement and asks OS to kill it
- Abort: parent process terminates execution of child process
- Threads
- Every thread has its own registers, PC and stack, code and data can be shared
- Motivation for threads
- Multi-processing is expensive, processes have separate memory, so each time all state information needs to be copied
- Multi-threading is cheaper, only stack, PC, registers need to be copied
- Benefits or threads
- Responsiveness: interactive program can keep running even if one thread blocks
- Resource sharing: code, address space sharing comes for free with threads, for processes, code copying required for former, IPC for latter
- Economy: slightly cheaper to context switch, much cheaper to create
- Utilization of multiprocessors, better parallelism and scalability
- Thread Control Blocks (TCB)
- Break the PCB into two pieces:
- Information related to process execution in TCB: thread register, stack pointer, cpu registers, cpu scheduling information, pending I/O information
- Other information associated with process: memory management information (heap, global variables), accounting information
- Break the PCB into two pieces:
- User threads v.s. kernel threads
- Kernel thread: managed by OS with multi-threading architecture, it's the unit of execution that is scheduled by the kernel on the cpu
- User thread: implemented with treads library, supported above the kernel and are managed without kernel support
- The mapping between user thread and kernel thread can be many-to-one, one-to-one and many-to-many
- Pros and cons
- User thread
- Pros
- Can be implemented on an os that does not support threads
- Thread switching is faster trapping to the kernel
- Thread scheduling is very fast
- Each process can have its own scheduling algorithm
- Cons
- Blocking system calls (if one thread sends a system call, the os does not know the process has multi-threading, so the whole process is blocked)
- Page faults
- Threads need to voluntarily give up the cpu for multiprogramming
- Pros
- Kernel thread
- Pros
- No run-time system needed in each process
- No thread table in each process
- Blocking system calls are not a problem (kernel knows there is multi-threading in the process, so cpu scheduler assigns another thread to run)
- Cons
- If thread operations are common, much kernel overhead will be incurred
- If a signal is sent to a process, should the process handles it or assigns a thread to handle it?
- Slower that user-space threads
- Pros
- User thread
- Thread library in Java
- Threads in Java are managed by JVM, mapping to kernel threads depends on the OS
- Thread creation
- Extends
Threadclass, overriderun()method1
2
3
4
5
6
7
8
9
10
11
12
13
14class MyThread extends Thread {
public void run() {
// code here
}
}
public class Test{
public static void main(String[] args) {
Thread thread = new MyThread();
thread.start();
}
} - Implements
Runnableinterface, overriderun()method1
2
3
4
5
6
7
8
9
10
11
12
13class MyThread implements Runnable {
public void run() {
// code here
}
}
public class Test {
public static void main(String[] args) {
Thread thread = new Thread(new MyThread());
thread.start();
}
}
- Extends
Lecture 08 2022/02/10
- Status of a thread
- init, run, blocked, dead
- Interaction between parent and child thread
- Execute concurrently: call
child.start()in the parent thread - Parent suspend until child is done: call
child.join()in the parent thread, noticejoinmethod can throwInterruptedexception, so you should use a try-catch clause. Noticechild.start()should be called beforechild.join()is called - Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class MyThread implements Runnable {
public void run() {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("Child is interrupted!");
break;
}
}
}
}
public class Test {
public static void main(String[] args) {
Thread thread = new Thread(new MyThread());
thread.start();
try {
thread.interrupt();
thread.join();
} catch(InterruptedException e) {
System.out.println("Parent interrupts child!");
}
System.out.println("Parent is done!")
}
}
- Execute concurrently: call
- Cancel threads
- Call
child.interrupt()to interrupt the child thread, it sets the interrupt flag in the child thread Thread.currentThread().isInterrupted()method in the child thread: returns boolean valueinterrupted()method in the child thread: returns boolean value, and clears the interrupt flag
- Call
- Inter-process communication
- Most modern Os does not support inter-process communication
- Independent processes are not affected by execution of other processes
- Communication methods
- Message passing: direct/indirect messaging, asynchronous/synchronous messaging
- Shared memory
- Producer-consumer problem
- Buffer size: unbounded/bounded
- Reader/writer problem
- Mutual exclusion problem
Lecture 09 2022/02/15
- Scheduling
- Multiprogramming goal: avoid cpu idle time, some process is using the cpu all the time
- Typical process execution flow: cpu burst and I/O burst
- CPU-bound and I/O-bound process
- Two types of scheduling:
- No-preemptive : processes only give up cpu voluntarily
- Preemptive: processes also may be preempted by an interrupt
- Clock interrupt
- This is how system keeps track of time, the interrupt happens at periodic intervals
- This is a hardware system clock on the motherboard, it's not the same as the cpu clock
- The clock interrupt has very high priority
- Scheduling policies
- Criteria for effectiveness of scheduling policies
- Throughput
- Measured in amount of processes completed/ time unit
- Turnaround time
- Turnaround time = process completion time - process creation time(arrival time)
- Turnaround time = waiting time + execution time
- Waiting time
- Waiting time = waiting time in the ready queue
- If a process is preempted, then the waiting time is the sum of all time waiting time
- Compared with turnaround time, waiting time does not have a penalty for processes with long execution time
- Response time
- Response time = time of 1st response is produced- time of creation
- Overhead
- Time spent related to scheduling
- Fairness
- How much variation in waiting time, want to avoid process starvation
- Dispatch time
- The time it takes to choose next running process
- Dispatch time = schedule time + context switch time
- Throughput
- Generally it's not possible to meet all performance criteria for one scheduling policy
- Measures
- CPU utilization: the higher, the better
- Throughput: the higher, the better
- Turnaround time: the lower, the better
- Waiting time: the lower, the better
- Response time: the lower, the better
- Criteria for effectiveness of scheduling policies
- First Come First Serve(FCFS)
- Idea: processes are served according their arrival order
- This is a non-preemptive scheduling policy
- Pros:
- Easy to implement
- No starvation, so it's fair
- Cons
- Convoy effect: order of arrival determines performance. If a long process arrives first, then the average turnaround time, average waiting time will be long
Lecture 10 2022/02/17
- Shortest Job First
- Idea:
- Non-preemptive version: If processes arrive at the same time, choose the one with the minimal cpu burst execute first. If processes arrive at different time, whenever a process finishes, select from the arrived processes the one that has the minimal cup burst
- Preemptive version: currently running process can be preempted if new process arrives with shorter remaining CPU burst
- A problem: in reality, we do not know the amount of cpu burst, so we
need to use prediction
- Equation:
- If
- If
- Equation:
- Pros
- Optimal(minimal) for average turnaround time and for average waiting time
- Cons
- Starves processes with long cpu bursts
- It's hard to predict cpu burst time
- Idea:
- Priority-Based
- Idea: the process withe the highest priority is executed first
- SJF can be seen as a special case for priority-based scheduling in that processes with shorter cpu burst are assigned higher priorities
- Priority-based scheduling can be either non-preemptive or preemptive
- Pros
- Reflects relative importance of processes
- Cons
- Can cause starvation of low priority processes (can use aging to tackle this problem)
- Round-robin
- Each process gets a small unit of cpu time (time quantum), after quantum has elapsed, the running process is preempted and added to the end of ready queue. If a process finished in one time quantum, the next process starts immediately
- This is a preemptive only scheduling policy
- If there are n processes, and time quantum is q, then in one round, each process is executed for at most q/n time, each process waits up to (n - 1)q/n time
- If the time quantum is too large, then Round-robin becomes FCFS, if the time quantum is too small, then there will be too many context switch overheads
- Pros
- Fairness
- Lower response time than SJF
- Cons
- High context switch overhead
- Higher turnaround time than SJF
- Multilevel Queue
Idea: ready queue is partitioned into separate queues, each with its own scheduling algorithm
Inter-queue scheduling
- Fixed priority: each queue has its own priority, high priority queues are served before low priority queues, this may lead to starvation in low priority queues
- Time-slice: each queue gets a reserved slice of cpu time to schedule amongst its processes (e.g. 80% for higher priority queue, 20% for lower priority queue, this can be achieved using round-robin inter-queue scheduling algorithm, and use randomization with lottery system to achieve the respective percentage)
In UNIX, there are 32 queues, 0-7 are system queues, 8-31 are user queues. User processes can be moved between different user queues by changing its priority level
Multilevel Feedback Queue (MFQ)
Processes can move between queues
Use MFQ to mimic SJF
- Higher priority queue uses RR with low time quantum (short jobs can finish here, other jobs are downgraded to lower priority queues after short time quantum elapses)
- Lower priority queue uses RR with high time quantum
- Processes downgrade their priorities when they get older
Example:
Process Burst Time Arrival Time P1 125 0 P2 50 0 P3 500 0 P4 175 0 P5 200 250 P6 50 250
The result is
Process Arrival Time Q1 Q2 Q3 Completion Time Turnaround Time P1 0 0-75 400-450 450 450 P2 0 75-125 0 125 125 P3 0 125-200 450-600 825-1100 1100 1100 P4 0 200-275 600-700 700 700 P5 250 275-350 700-825 825 575 P6 250 350-400 400 150
Lecture 11 2022/03/01
- Real-time scheduling
- Real-time means process must/should complete by some deadline
- Hard real-time
- Definition: process must complete by some deadline, this requires dedicated scheduler
- Idea:
- Determine feasible processes(deadline - current time
- Greedy heuristic: choose process with min value of [deadline - current time - cpu burst]
- Determine feasible processes(deadline - current time
- Soft real-time
- Definition: process should complete by some deadline, this can be integrated into Multi-level feedback queues
- Idea: processes should not be demoted, requires strict time-slices
- Scheduling examples
- Windows
- Windows uses priority-based, doubly preemptive scheduling, preemption occurs with both end of time quantum and arrival of higher-priority thread
- Thread priority has different components
- Statically assigned priority class
- Dynamically assigned relative priority (expiration of time quantum, satisfaction of I/O)
- FG processes are given 3 times priority of the BG ones
- Windows 7 add user-mode scheduling(UMS): applications create and manage threads independent of kernel
- Linux
- Linux has two classes of processes: real-time processes and time-shared processes
- Real-time processes: have soft deadline, have highest-priority, are within same priority class, use FCFS or RR as scheduling policy
- Timesharing processes: default ones, have credits(similar to aging), initialize credits based on priority and history, lose credits when time-sliced out, scheduler chooses process with the most credits
- Java JVM
- Java uses preemptive, priority-based scheduling. Preemption happens at the arrival of higher priority thread
yield(): running thread yields to another thread of equal priority- Thread priorities:
Thread.MIN_PRIORITY,Thread.MAX_PRIORITY,Thread.NORM_PRIORITY
- Windows
- Synchronization overview
- Idea: processes, threads use shared data access to communicate. Shared data access can result in data inconsistencies and unpredictable processes/threads behaviors. So synchronization is needed to prevent that
- Definition
- Race condition: outcome of thread execution depends on timing of threads
- Synchronization: use of atomic operations to ensure correct cooperation amongst threads
- Mutual exclusion: ensure that only one thread does a particular thing
- Critical section: piece of code that only on thread can execute at any time (if multiple threads access critical section, there will be data inconsistencies)
- Lock: construct that prevents someone from doing something
- Starvation: occurs when one or more threads never gets access to critical section
Lecture 12 2022/03/04
- The milk problem: suppose there is not milk, and we want only one
bottle of milk
- Solution 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Person A
if (noMilk) {
if (noNote) {
leave note;
buy milk;
remove note;
}
}
// Person B
if (noMilk) {
if (noNote) {
leave note;
buy milk;
remove note;
}
}- This one does not work, think of context switch after the second if, both will leave a note and buy a bottle of milk, then there will be two bottles of milk in the end
- Solution 2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Person A
leave noteA;
if (noNoteB) {
if (noMilk) {
buy milk;
}
}
remove noteA;
// Person B
leave noteB;
if (noNoteA) {
if (noMilk) {
buy milk;
}
}
remove noteB;- This one does not work, think of the situation A starts first, there is a context switch after the first if to B, and another switch back to A after executing the first line of B, then neither of A or B will buy a bottle of milk
- Solution 3:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Person A
leave noteA;
// Denote this line X
while (noteB) {
skip;
}
if (noMilk) {
buy milk;
}
remove noteA;
// Person B
leave noteB;
// Denote this line Y
if (noNoteA) {
if (noMilk) {
buy milk;
}
}
remove noteB;- This one works
- X and Y are lines that after which critical sections are executed, so we think of situations here
- At Y:
- If noNoteA: A has not start, or A has already bought milk, B can buy milk if no milk, or does not buy milk if there is milk
- If noteA: A is waiting B to quit, or A is buying milk, so B does buy and quit
- At X:
- If noNoteB: B has not start, or B has ready bought milk, A can buy milk if no milk, or does not buy milk if there is milk
- If noteB: B is waiting A to quit, or B is buying milk, so A waits B to remove note, then checks if there is milk to decide whether to buy or not
- Disadvantages:
- This approach is complicated
- This is not a symmetric solution, code needs to be different for each process, can not be generalized to multiple processes situations easily
- A is busy waiting
- A is favored: if A and B have different goals, A is more favored than B
- This one works
- Better solutions
- Have hardware provide better primitives than atomic LOAD, STORE
- Build higher-level programming abstraction on above hardware
instructions, for example: lock with atomic
acquire()andrelease() - Milk solution example
1
2
3
4
5
6// Person A and Person B
lock.acquire();
if (noMilk) {
buy milk;
}
lock.release();
- Solution 1
- The critical section problem
- Idea: only one thread is executing the critical section at a time to avoid race condition
- Examples
- Milk synchronization:
if (noMilk) {buy milk} - Bank transfer synchronization:
acc1 -= amount; acc2 += amount; - Producer consumer problem:
- Problems in the producer's method
1
2
3
4
5
6
7
8
9
10public void insert(Object item) {
while (count == size) {
skip;
}
count ++;
// If context switch happens here, then consumer thinks there is one
// more items than there actually is
buffer[in] = item;
in = (in + 1) % size;
} - Additional problems:
count++/count--1
2
3
4// There can be context switches between these three instructions
LOAD R1, count
INC R1 // DEC R1 for count--
STORE R1, count
- Problems in the producer's method
- Milk synchronization:
- For efficiency consideration, it's important to identify the exact lines of code that is the critical section
- General form of threads
1
2
3
4
5
6while (true) {
entry code;
critical section;
exit code;
non-critical section;
} - General solution to critical section problems
- Clever algorithms
- Hardware-based solutions
- Hardware-based solutions + software abstractions
- Goals of solution
- Mutual exclusion
- Progress: no thread outside of its critical section should block other threads
- Bounded waiting: if a thread has already made a request to enter its critical section, then the amount of times other threads should only enter their critical sections for a bounded amount of times
- Software solution to critical section problems
- Strict alternation
- Idea: each thread take turns to get into its critical section
- Pseudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19shared int turn;
// Thread A
while (true) {
while (turn != 0) {
skip;
}
critical section;
turn = 1;
non-critical section;
}
// Thread B
while (true) {
while (turn != 1) {
skip;
}
critical section;
turn = 0;
non-critical section;
} - Strict alternation satisfies both mutual exclusion, bounded waiting, but does not satisfy progress
- Disadvantage:
- Does not satisfy progress
- Use busy waiting, waste lots of resources
- Faster threads can get blocked by slower ones
- After you
- Idea: thread specifies interest in entering critical section, and can only enter if other thread is not interested
- Pseudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21shared boolean flag0, flag1;
//Thread A
while (true) {
flag0 = true;
while (flag1) {
skip;
}
critical section;
flag0 = false;
non-critical section;
}
//Thread B
while (true) {
flag1 = true;
while (flag0) {
skip;
}
critical section;
flag1 = false;
non-critical section;
} - After you satisfies mutual exclusion, but does not satisfy progress and bounded waiting
- Strict alternation
Lecture 13 2022/03/10
- Software solution to critical section problems
- Peterson's algorithm
- Idea: combination of strict alternation and after you, threads take turns to get into critical section but a thread skips its turn if it's not interested and another thread is
- Pesudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20shared int turn;
shared boolean flag0, flag1;
// Thread A
flag0 = true;
turn = 1;
while (turn == 1 && flag1) {
skip;
}
critical section;
flag0 = false;
non-critical section;
// Thread B
flag1 = true;
turn = 0;
while (turn == 0 && flag0) {
skip;
}
critical section;
flag1 = false;
non-critical section; - Peterson's algorithm satisfies mutual exclusion, progress and bounded waiting
- Peterson's algorithm
- Hardware solutions to critical section problems
- Disabling interrupts
- Idea: disable interrupts before entering critical section and enable interrupts after exiting critical section
- Pseudocode
1
2
3
4
5
6
7// All threads
while (true) {
disable interrupts;
critical section;
enable interrupts;
non-critical section;
} - Comments
- Advantages: this solution is easy to implement
- Disadvantages:
- Overkill: disables all interrupts(I/O), disallows concurrency with threads in non-critical sections
- Does not work for multi-core systems, because each cor has its own interrupts, so threads on different cores can access their critical sections at the same time
- Test and set
- An assembly command called TS(test and set), it's an atomic operation
- What does
TS(i)do- Save the value of
Mem[i](Mem[i] stores a boolean value of a lock) - Set
Mem[i] = True - Return the original value of
Mem[i]
- Save the value of
- If TS(i) returns True, then the lock is locked, so we cannot access the critical section
- Solve the critical section problem with TS
1
2
3
4
5
6
7
8
9shared bool lock = false;
while (true) {
while (ts(lock)) {
skip;
}
critical section;
lock = false;
non-critical section;
} - Comments
- Advantages: easy to use for critical sections, not easy to use for other synchronization problems
- Disadvantages: busy waiting is involved, can be expensive on multi cores
- Semaphores: software abstraction of hardware
- Idea: a semaphore is a data structure consisting of an integer lock
with a waiting queue, it provides thread safe operations
init(n): n threads are allowed access to resource at a timeacquire(): thread code calls to gain accessrelease(): thread code calls to relinquish access
- Binary semaphore: n = 1, only one thread can hold lock at a time
- Counting semaphore: n threads can hold lock at a time
- A semaphore can be either unlocked or locked by a thread with other threads waiting in the queue
- Critical section solved with binary semaphore
1
2
3
4
5
6
7shared binary semaphore S = 1;
while (true) {
acquire(S);
critical section;
release(S);
non-critical section;
}
- Idea: a semaphore is a data structure consisting of an integer lock
with a waiting queue, it provides thread safe operations
Lecture 14 2022/03/15
- Bounded buffer problem
- Shared buffer between producer thread and consumer thread
- Terminology
- buffer: circular queue, shared by all threads
- in: a pointer that points to next spot to insert into buffer, shared by all producer threads
- out: a pointer that points to next spot to remove from buffer, shared by all consumer threads
- Full buffer: ensure producer does not try to insert into a full buffer (wait until not full)
- Empty buffer: ensure consumer does not try to remove from an empty buffer (wait until not empty)
- Semaphores (buffer size N)
empty: measure the amount of empty spots in the buffer, initialized to be N, shared by all producers, locked after N producer threads acquire the the semaphore (which means the buffer is full)full: measure the amount of full spots in the buffer, initialized to be 0, shared by all consumers, unlock after 1 producer thread release the semaphore (which means the buffer is not empty, so the consumer can start consuming)mutex: binary semaphore, shared by all threads, used to ensure atomic update of shared variables
- Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30Semaphore mutex = new Semaphore(1);
Semaphore empty = new Semaphore(N);
Semaphore full = new Semaphore(0);
int in = 0;
int out = 0;
T[] buffer = new CircularQueue<T>(N);
//producer thread
while (true) {
empty.acquire();
// This line should be after empty.acquire(), because if you acquire mutex first
// and the buffer is full, then there is no way for consumers to acquire the mutex
// and increase the empty semaphore
mutex.acquire();
buffer[in] = new T();
in = (in + 1) % N;
// This line can be after the release of the full semaphore, but efficiency is
// reduced then
mutex.release();
full.release();
}
// consumer thread
while (true) {
full.acquire();
mutex.acquire();
T item = buffer[out];
out = (out + 1) % N;
mutex.release();
empty.release();
} - Bounded buffer with only one binary semaphore and spin lock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public void insert (T item) {
mutex.acquire();
while (count === N) {
mutex.release();
// Context switch can happen here, allowing consumers to remove
mutex.acquire();
}
// Insert goes here
}
public T remove() {
T item;
mutex.acquire();
while (count == 0) {
mutex.release();
// Context switch can happen here, allowing producers to insert
mutex.acquire();
}
// Remove goes here
return item;
} - The single mutex and spin lock approach does eliminate inconsistencies, but it involves busy waiting and waste of CPU resources
Lecture 15 2022/03/17
- Readers-writers problem
- Idea:
- A buffer of updatable data
- Two type of threads: readers and writers
- Synchronization rules: can allow access of either any number of readers at a time, or exactly one writer
- Database example
- Read is query: queries do not change contents of database, several can execute concurrently
- Write is update: if an update is taking place, it cannot allow either reads or other writes
- Approach 1: a reader-favored solution
- Idea
rcount: the number of readers that is currently reading the databasemutex: a binary semaphore that is used to guard the modification of rcount among readersrwlock: a binary semaphore shared among readers and writers- It can be acquired by a writer to ensure that no other writer is updating the databsae concurrently
- It can be acquired by the first reader to ensure that no writer is updating the database when there are readers reading the database
- It should be released by the last reader to allow writers to update the database
- Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// Shared variables initialization
int rcount = 0;
Semaphore mutex = new Semaphore(1);
Semaphore rwlock = new Semaphore(1);
// Writer thread
while (true) {
// If this acquire method does not stuck, it means no other writer is updating
// the database and no other readers are reading the database
rwlock.acquire();
// Update the database
rwlock.release();
}
// Reader thread
while (true) {
// Use mutex to ensure exclusive access to rcount
mutex.acquire();
rcount ++;
// If the reader is the first one, then it should not let writers update the
// database, so it should acquire the rwlock
if (rcount == 1) {
rwlock.acquire();
}
mutex.release();
// Read database
// Use mutex to ensure exclusive access to rcount
mutex.acquire();
rcount --;
// If the reader is the last one, then it should release the rwlock to let
// writers run
if (rcount == 0) {
rwlock.release();
}
mutex.release();
} - Performance: Give high throughout (there can be many readers active at a time), but bounded wait not satisfied (the writers may wait indefinitely)
- This is a readers-favored solution: as long as the writer starts after the 1st reader, it needs to wait for all readers to finish to run
- Idea
- Approach 2: a writers-favored solution:
- Idea
rcount,wcount,mutex1for rcount,mutex2for wcount,rlock,wlock- Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49// Shared variables initialization
int rcount = 0;
int wcount = 0;
Semaphore mutex1 = new Semaphore(1);
Semaphore mutex2 = new Semaphore(1);
Semaphore rlock = new Semaphore(1);
Semaphore wlock = new Semaphore(1);
// Reader thread
while (true) {
// Use wlock to wait writers to finish updating the database
wlock.acquire();
mutex1.acquire();
rcount ++;
if (rcount == 1) {
// Lock the database so no update can happen during writing
rlock.acquire();
}
mutex1.release();
wlock.release();
//Read database
mutex1.acquire();
rcount --;
if (rcount == 0) {
rlock.release();
}
mutex1.release();
}
// Writer thread
while (true) {
mutex2.acquire();
wcount ++;
if (wcount == 1) {
wlock.acquire();
}
mutex2.release();
// If there are readers reading the database, then wait; if not, block all
// subsequent readers
rlock.acquire();
// Update database
rlock.release();
mutex2.acquire();
wcount --;
if (wcount == 0) {
wlock.release();
}
mutex2.release();
} - Performance: the writers can run ASAP, but readers can wait indefinitely
- Idea
- Idea:
- Dining Philosopher
- Idea
- N philosophers sit a table with N chopsticks, each philosopher shares 2 chopsticks with her left and right neighbor
- Each philosopher thinks for a while, gets hungry then tries to grab both chopsticks next to him, and eats then releases chopsticks
- The question is how to serve dishes for the philosophers
- Solution 1: ensure only one philosopher grabs a given chopstick
- Implementation
1
2
3
4
5
6
7
8
9
10
11
12// Shared variables initialization
// An array of N binary semaphores
Semaphore[] chopsticks = new Semaphore[N];
// For philosopher i thread
while (true) {
chopsticks[i].acquire();
chopsticks[(i + 1) % N].acquire();
// Eat
chopsticks[i].release();
chopsticks[(i + 1) % N].release();
// Think
} - Performance: this may result in a deadlock
- Implementation
- Solution 2: ensure only one philosopher grabs both her chopsticks at
a time
- Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14// Shared variables initialization
Semaphore mutex = new Semaphore(1);
Semaphore[] chopsticks = new Semaphore[N];
// For philosopher i thread
while (true) {
mutex.acquire();
chopsticks[i].acquire();
chopsticks[(i + 1) % N].acquire();
mutex.release();
// Eat
chopsticks[i].release();
chopsticks[(i + 1) % N].release();
// Think
} - Performance: this does not result in a deadlock, but philosophers that are not eating (not in the critical section) can block following philosophers (when she acquires the mutex, but is blocked by acquiring chopsticks)
- Implementation
- Solution 3: synchronize philosophers states (hungry, eating,
thinking) rather than synchronizing chopsticks
- Implementation ## Lecture 16 2022/03/22
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30// Shared variables initialization
// states[i] can be hungry, eating and thinking
State[] states = new State[N];
// if phils[i] is locked, she cannot eat, if phils[i] is unlocked, she can eat
Semaphore[] phils = new Semaphore[N];
// Use mutex to avoid race condition in states
Semaphore mutex = new Semaphore(1);
void seekToEat(i) {
if (states[i] == hungry && states[(i - 1) % N] != eating && states[(i + 1) % N] != eating) {
states[i] = eating;
phils[i].release();
}
}
// For philosopher i thread
while (true) {
mutex.acquire();
states[i] = hungry;
seekToEat(i);
mutex.release();
phils[i].acquire();
// Eat
mutex.acquire();
states[i] = thinking;
seekToEat((i + 1) % N);
seekToEat((i - 1) % N);
mutext.release();
// Think
}
- Implementation
- Idea
- Alternatives to Semaphores: Monitors
- Performance of semaphores
- Semaphores accomplishes two tasks:
- Mutual exclusion of shared memory (mutex)
- Scheduling constraints: down and up(counting semaphore)
- If the down and up are scatter among several processes, problems may
occur
- If the order of down is wrong, deadlocks may occur
- If the order of up is wrong, performance may be poor
- We want something that is simple and easy
- Semaphores accomplishes two tasks:
- Implementation of monitors
- A package that consists of a collection of procedures, variables and data structures
- Compiler implements the mutual exclusion on monitor entries
- Performance of semaphores
- Monitors
- Definition: a monitor is an abstract data type that provides a high-level form of process synchronization
Thread.yield(): if a thread calls this method, it voluntarily relinquishes the CPU- If there are threads with equal or higher priorities, then the thread changes its state from running to ready and gives up the CPU
- If there are no threads with equal or higher priorities, then the thread continues to run
- Bounded buffer problem revisited
- We can replace the mutex and spin lock solution with
Thread.yield() - Since
Thread.yield()does not ensure mutual exclusion, we can change the insert and remove method tosynchronized - Such synchronized insert and remove methods can result in deadlocks
- We can replace the mutex and spin lock solution with
- Synchronized methods
- All objects in Java have an associated lock
- Calling synchronized method requires owning the lock, if the calling thread does not own the lock, it is placed in the entry set for the object's lock, the lock is released when the active thread exits the synchronized method
- Condition variables
wait()andsignal()
- Java thread methods
t.wait(): t release the object's lock, change the state of t to blocked, t is placed in the wait sett.nofity(): select a thread t' from the wait list of the object's lock, move t' to the entry set, change the state of t' to ready
Lecture 17 2022/03/24
- Deadlock
- Definition: deadlock occurs in a set of processes when every process in the set is blocked and waiting for an even that can only be caused by another process in the set
- Four necessary but not sufficient conditions of deadlock
- Mutual exclusion: only one process can use a resource at a time
- Hold & wait: process holding more than one resources is waiting to acquire others hold by other processes
- No preemption: resources only released by processes voluntarily when they finish using the resources
- Circular wait: there exists a set of waiting processes,
- An deadlock example
1
2
3
4
5
6
7
8
9Semaphore m1 = new Semaphore(1); // binary semaphore m1
Semaphore m2 = new Semaphore(1); // binary semaphore m2
// Thread A
m1.acquire(); // Context switch after this line to Thread B
m2.acquire();
// Thread B
m2.acquire();
m1.acquire(); - Starvation is different from deadlock
- For a deadlock: all threads are suspended
- For a starvation: only part of threads are suspended (for example, threads with lower priorities in the priority scheduling policy)
- Deadlock problem descriptions
- Models
- Resource types:
- Each resource type
- Each process requests a resource (wait until the resource is granted), use the resource, and release the resource
- System table records if a resource is free or not, process it allocated, and queue for processes waiting for each resource
- Resource types:
- Models
- Resource allocation graph
- V: set of vertices
- P =
- R =
- P =
- E: set of edges
- Request edge:
- Assignment edge:
- Request edge:
- Some interpretations
- No cycle, then no deadlock
- Cycle and n instances per resource type, then possible deadlock
- Cycle and one instance per resource type, then deadlock for sure
- Processes that are not in a cycle can also be in deadlock
- V: set of vertices
- Dealing with deadlock
- Prevention: breaking one of the three conditions with
deadlock(mutual exclusion cannot be broken), so deadlocks will not occur
- Break hold & wait: before execution, processes try to acquire all resources they need, if they cannot do so, they are allocated no resources
- Break preemption: if a process holds some resources and requires more but cannot get them, then the process releases all resources it currently holds
- Break circular wait: processes must request resources in an increasing order
- Prevention: breaking one of the three conditions with
deadlock(mutual exclusion cannot be broken), so deadlocks will not occur
Lecture 18 2022/03/29
- Deadlock Avoidance
- Does not break the necessary conditions for deadlock, but monitor the system, and if a request will lead the system to unsafe state, such request is rejected
- System state
- In a safe state, there is no possibility of deadlock, we can find a safe sequence to grant the requests in a safe state
- In an unsafe state, there is possibility of deadlock
- Avoidance: never enter an unsafe state
- Banker's algorithm: deadlock avoidance
- Terminology
Available: array with length m, available resources for each resource typeMax: n * m matrix, process i request max[i][j] instances of resource jAllocation: n * m matrix, process i is allocated allocation[i][j] instances of resource jNeed: n * m matrix, need[i][j] = max[i][j] - allocation[i][j]
- Something to remember
- Available can be calculated from total available resources and allocated resources
- If a request is granted, then the allocated resources should be added to available resources
- Check if a request should be granted: add the request to allocation, if we can find a safe sequence, then the result is a safe state, so the request should be granted, but if somewhere in the middle we cannot grant any more process for execution, the the system enters an unsafe state, so the request should not be granted
- Terminology
- Deadlock detection + recovery
- Idea: allow system to enter deadlocked states, periodically run deadlock detection algorithm. If deadlock is detected, then run recovery scheme to break the deadlock
- Detection situation 1: each resource type has one instance
- Idea: we just need to check if there is a cycle in the resource allocation graph
- Algorithm: use DFS to check if a directed graph has a backward edge, then the system is in a deadlocked state, the time complexity is O(V + E)
Lecture 19 2022/03/31
- Deadlock detection + recovery (ctd)
- Detection situation 2: each resource types have multiple instances,
we use a detection algorithm that is similar to the banker's algorithm
- If some requests can be granted, then they are not deadlocked.
- The requests that cannot be granted are deadlocked
- Time complexity of the deadlock detection algorithm:
- The deadlock detection algorithm is expensive, therefore we do not run this deadlock detection algorithm after resource allocation. The frequency of the detection algorithm depends on how often a deadlock is likely to occur and how many processes will need to be rolled back
- Deadlock recovery
- Recovery approach 1: process termination
- Kill all deadlocked processes
- Kill one deadlocked process at a time until the deadlock cycle is eliminated (select the process to be killed based on priority, completion percentage, resources held, resources requested, etc.)
- Recovery approach 2: preempt resources from deadlocked processes
- Preemption cost should be minimal
- If a process is preempted, it should be rolled back to a previous safe state and restart from that state
- We need to ensure wo do not always preempt resources from the same process, which can avoid starvation of that process
- Recovery approach 1: process termination
- Detection situation 2: each resource types have multiple instances,
we use a detection algorithm that is similar to the banker's algorithm
- The Ostrich method
- As the deadlock can be very infrequently and the cost of handling can be very high, the OS can just pretend there are no deadlocks
- Most OSs use this method and let the programmers to handle deadlocks
- Memory Manager
- Memory manager is another resource manager component of the OS
- Responsibilities
- Memory allocation: responsible of allocating memory to processes
- Address mapping
- Address mapping allows to run the same code in different physical memory in different processes, and to support process address space abstraction
- Memory management unit (MMU) is responsible for mapping logical addresses generated by CPU instructions to physical addresses seen by memory controller
- MMU is usually on the same chip as the CPU
- Address mapping
- Logical addresses
- Generated by CPU instructions, is an abstraction of memory
- Logical addresses start at 0, and are contiguous
- Generating logical addresses
- At compile time
- At link/load time
- At execution time
- Logical address space is defined by base and limit registers. If the address is not in the range, there are traps to the OS
- Logical addresses
- Memory allocation
- Memory allocation goals
- High memory utilization: ensure as much memory is used as possible
- High concurrency: support as may processes as possible
- Memory allocation should be fast
- Memory allocation strategies
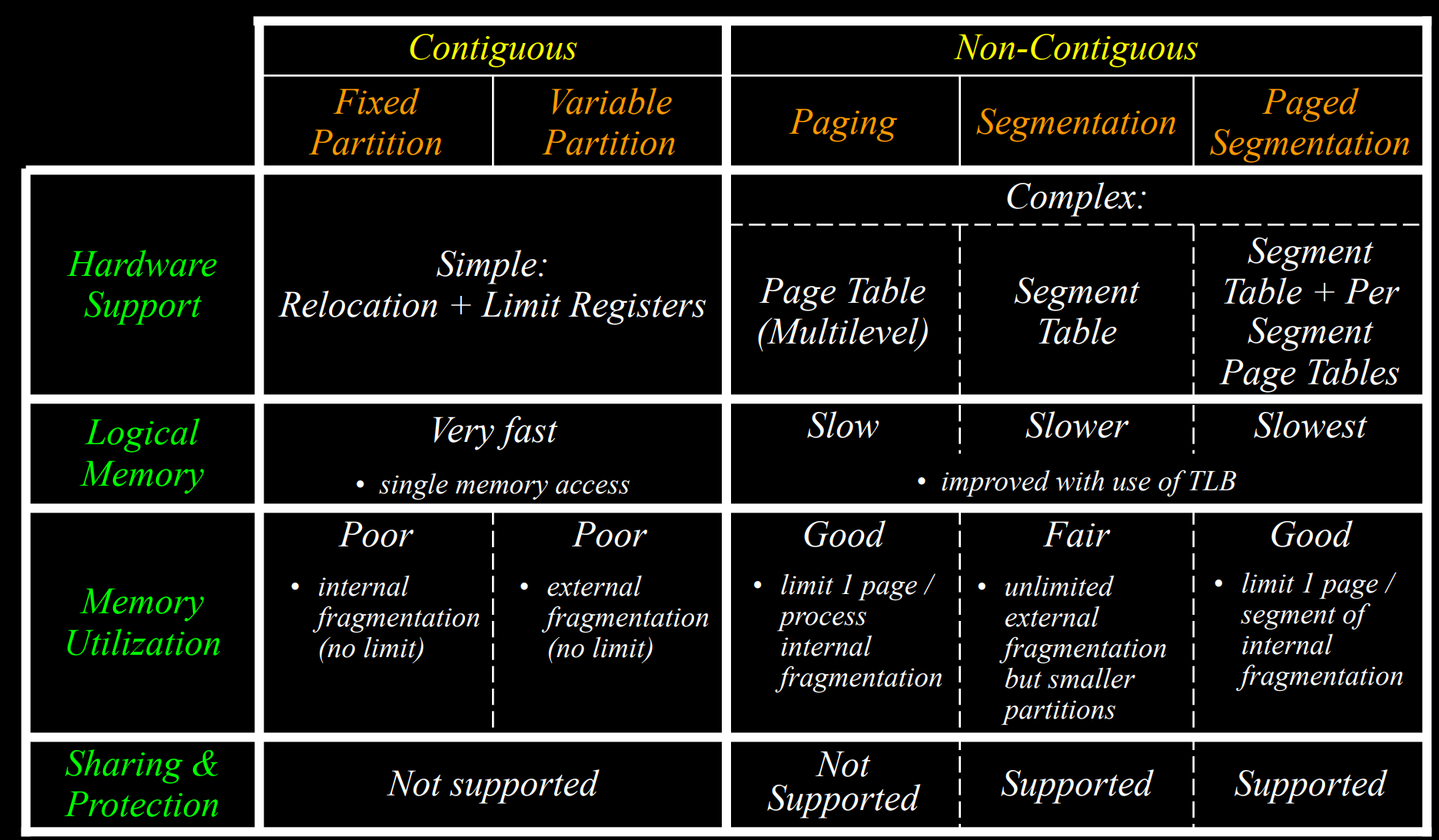
- Contiguous memory allocation
- Fixed partition allocation
- Idea: divide the physical address space into fixed partitions and allocate processes into the partitions. One partition can hold at most one process
- Implementation: requires the support of relocation (base) and limit register
- Issues:
- Internal fragmentation: when a process is allocated to a partition and parts of the partition is not used, such part is called the internal fragmentation
- We need to know in advance the memory needs of processes
- The memory needs of processes should not change during their lifetime
- Fixed partition allocation
- Contiguous memory allocation
- Memory allocation goals
Lecture 20 2022/04/05
- Memory allocation (ctd)
- Memory allocation strategies (ctd)
- Contiguous memory allocation (ctd)
- Variable partition allocation
- Idea: physical memory is not divide into fixed partitions, but has a set of holes from which memory can be assigned
- Allocation policies
- Best fit: choose the smallest feasible hole
- Worst fit: choose the largest feasible hole
- First fit: choose the first feasible hole (do not need to search the list)
- Next fit: choose the next feasible hole (do not need to search the list, do not need to start from the beginning)
- Issues:
- External fragmentation: the size of a hole may be larger than the needs of a process, the difference is called the external fragmentation
- External fragmentation can be periodically eliminated via compaction
- Comments
- Contiguous memory allocation is easy to implement and conceptualize
- Contiguous memory allocations is faster than non-contiguous memory allocation
- The memory utilization is poor
- Used by some early batch systems
- Variable partition allocation
- Non-contiguous memory allocation
- Idea: logical address space is partitioned, each partition is mapped to a contiguous chunk of physical memory
- Approach 1: paging, all chunks are the same size, chunks are physically determined
- Approach 2: segmentation, chunks are variably sized, chunks are logically determined
- Approach 3: paged segmentation, combination of paging and segmentation
- Comments:
- Better memory utilization: by dividing address space into smaller chunks, more memory fragments can be used
- More complex implementation
- The standard memory allocation system used by all OS today
- Contiguous memory allocation (ctd)
- Memory allocation strategies (ctd)
- Paging
- Basic idea
- Divide physical memory into fixed-size blocks called frames
- Divide logical memory into same-sized blocks called pages
- Within a page, memory is contiguous, but pages need not to be contiguous or in order
- Address translation
- Logical address = (p, d), physical address = (f, d)
- p: page number (index into page table which contains base address of corresponding frame f)
- d: page offset: added to base address to find location within page/frame
- Logical and physical addresses are binary, so the translation is actually in binary form
- Logical address = (p, d), physical address = (f, d)
- Basic idea
Lecture 21 2022/04/07
- Paging (ctd)
- Page table implementation
- Page table is kept in the main memory
- Each process use process special status registers:
- Page table base register (PTBR): location of page table for process
- Page table limit register(PTLR): size of process page table
- Issues with paging
- Two memory access problem: use TLB
- Page table is too large:
- Use two level page table
- Use inverted page table
- Use hashed page table
- Improve memory access with TLB
- The implementation of page table requires 2 memory accesses for each
operation
- Look up the frame location for this process in page table
- Loop up the offset in the frame to find the location of the data
- Use translation loop-aside buffer to solve the two memory access
problem
- TLB is a fast lookup hardware cache containing some page table entries
- Why TLB is fast
- TLB is cache, and cache is faster than memory
- Associative memory permits parallel search
- When doing to page table lookup, first look in the cache TLB, if no in cache (called TLB miss), look in memory page table
- Effective access time (EAT) with TLB
- If TLB misses, then the performance is even worse than the page table lookup with two memory accesses (additional access in TLB)
- Assumption
- Each memory access takes time of 1
- Each TLB access takes
- TLB hit ratio
- EAT =
- If the hit ratio
- If there is a TLB miss, then we need to update the TLB entries
- The implementation of page table requires 2 memory accesses for each
operation
- Two level page table
- Page table is stored contiguously in the physical memory
- In 32-bit virtual memory, 12 bits are used for offset, 20 bits are used for page table, page table entry size is 4 bytes, then page table size is 4 * 2 ^ (32 - 12) = 4MB
- In 32-bit virtual memory, 12 bits are used for offset, 10 bits are used for outer (primary) page table, 10 bits are used for inner (secondary) page table, page table entry size is 4 bytes, then outer page table size is 4 * 2 ^ 10 = 4KB, inner page table size is 4 * 2 ^ 10 = 4KB, there is one outer page table and 2 ^ 10 inner page tables
- In the above two level page table, one virtual address translation involves the outer page table and one inner page tables
- Inverted page table
- For ordinary page table, each process has a page table
- For inverted page table, there is only one page table for all processes
- Comments
- Reduced memory space
- Longer lookup time
- Difficult shared memory implementation
- Hashed page table
- Page number is hashed to hashed page table
- Page table implementation
Lecture 22 2022/04/14
- Segmentation
- Idea: similar to paging, but partitions of logical address space/physical memory are variable, not fixed. Partition the logical address into text segment, stack segment, etc. Each segment itself is continuous, but the page table of a process as a whole is not.
- Architecture
- Logical addresses = (s, d)
- One process has one segment table
- Each process PCB holds segment table base register (STBR) and segment table length register(STLR). If a logical address is invalid, trap to the OS
- Issues with segmentation
- Two memory accesses problem: use TLB
- Segment table is too large: use paged segmentation: segmentation based allocation, but each segment is paged
- Comments on segmentation
- Easier to implement protection: text segment should be read-only, other segments may be non-executable. Page in the paging scheme can contain both code and data
- Easier to implement sharing: same text segment can be used by multiple processes concurrently
- Summary
- Virtual memory
- Motivation: increase the degree of multiprogramming in a running system
- Means
- High memory utilization, flexible memory allocation: allow allocated memory to be non-contiguous
- Swapping and virtual memory: allow some process to have address space dynamically mapped to physical memory
- Swapping
- Idea: ready or blocked processes have no physical memory allocation, instead, their address spaces are mapped to disk
- Processes can be swapped out to disk and swapped into memory dynamically
- Comments:
- Multiprogramming is limited not to memory but disk
- Easy to implement
- Expensive: involves a lot of disk I/O
- Time variable: depends on process size
- Virtual memory
- Idea: ready, blocked, or running process have some (but not all) of their allocation of physical memory
- Implementation: demand paging/demand segmentation
- Demand paging
- Idea: bring a page into memory only when it's referenced (read or written)
- Implementation
- Add valid/invalid bit to each page table entry: 1 is valid, which means the page is in memory, 0 is invalid, which means the page is not in memory
- Page mapping algorithm
- Logical address = (p, d)
- Search p in page table, if valid, convert p to f and get physical address = (f, d). If invalid, trap to page fault routine in OS to bring p into a free frame and update page table, then restart translation (during page fault, control is passed to OS, and when the handling process is done, control is returned to the process, the process does not know where to start from during execution, and it cannot start in the middle of an instruction, so it needs to restart)
- Submit memory request with (f, d)
- Pre-paging: load working set pages into memory before the process starts
Lecture 23 2022/04/26
- Virtual memory
- Page replacement
- If there is no free frame, then we need to replace a existing page in the memory using replacement algorithm
- Page replacement algorithms
- Goal: minimize number of page faults
- If page fault rate is
- Algorithms
- FIFO:
- Replace pages that has the oldest time when it was brought into the memory is replaced
- Belady' anomaly: when the number of allocated frames increases, page fault rate increases
- Optimal: replace the page that will not be used for the longest period time
- LRU: replace the page that hasn't been used for the longest period time
- NRU: not recently used
- LFU: replace page referenced fewest times
- FIFO:
- Frame allocation
- Idea: we have one set of frames but multiple processes, the problem is how to allocate the processes
- Goal:
- Minimize page fault rates
- Avoid any process thrashing
- Allocation policy
- Equitable: each process get even share of frames
- Proportional allocation: each process gets proportional share of frames
- Priority-based allocation: process with higher priority gets more frames
- Local allocation
- Idea: assign a process some number of frames when it is created, when page fault requires page replacement, replace a frame the process itself owns
- Issue: thrashing
- Comment:
- Does not use local allocation
- We need to know the set of current processes
- We need to assume the process' needs do not change over its lifetime
- We need to assume frame availability does not change over a process' lifetime
- Global allocation
- Idea: all processes have access to all frames, when replacement is needed, a process can replace a page owned by anyone
- Issue: thrashing is still possible
- Working set: a set of pages that a process is currently using
- If entire working set is in memory, there are no page faults at all
- If there is insufficient space for working set, thrashing may occur
- Use working set algorithm and adaptive algorithm (page fault
frequency scheme) to deal with thrashing
- Locality model: in order to avoid thrashing, we need to provide the pages that a process needs. We can say the pages that a process currently uses is the pages it needs, the view is called the locality model
- Working set model
- Use parameter
- Working set of a process at time
- Allocation algorithm
- Find the working set for each page
- If there are more pages in the working sets of all processes than the available frames, some processes must be suspended
- Otherwise, allocate processes frames according to their working sets
- If there are available frames after allocation, we can increase the number of multiprogramming and allow more processes to run
- Issues:
- Working set size
- Maintain the working set of each process is too expensive
- Working set size
- Use parameter
- Page fault frequency (PFF) scheme
- We can avoid thrashing by controlling the frequency of page faults
- If the page fault rate is high, we give the process more frames
- If the page fault rate is low, we know the process has too many frames and can remove some frames
- If the page fault rate is high, but there are no available frames, we need to swap out some processes
- Page replacement
Book contents
- Introduction
- What does os do Ch 1.1
- Computer system: hardware, operating system, application program, user
- Programs
- OS: one program running at all time on the computer, it's the kernel
- System program: associated with the os, but not necessarily part of the kernel
- Application programs: all programs not associated with the os
- Computer system organization Ch 1.2
- A modern general-purpose computer system consists of one or more CPUs and a number of device controllers connected through a common bus that provides access between components and shared memory
- OS has a device driver (software) for each device controller (hardware)
- CPU and device controller can execute in parallel, competing for memory, a memory controller synchronizes access to the memory
- Interrupt
- Interrupts are used throughout modern operating system to handle asynchronous events
- I/O operation read:
- Device driver loads appropriate registers into the device controller
- Device controller examines the registers and determines what action should take
- The controller transfers data from device to the a buffer in controller
- When data transfer is done, device controller informs device driver via interrupt
- The device driver then gives control to other parts of os
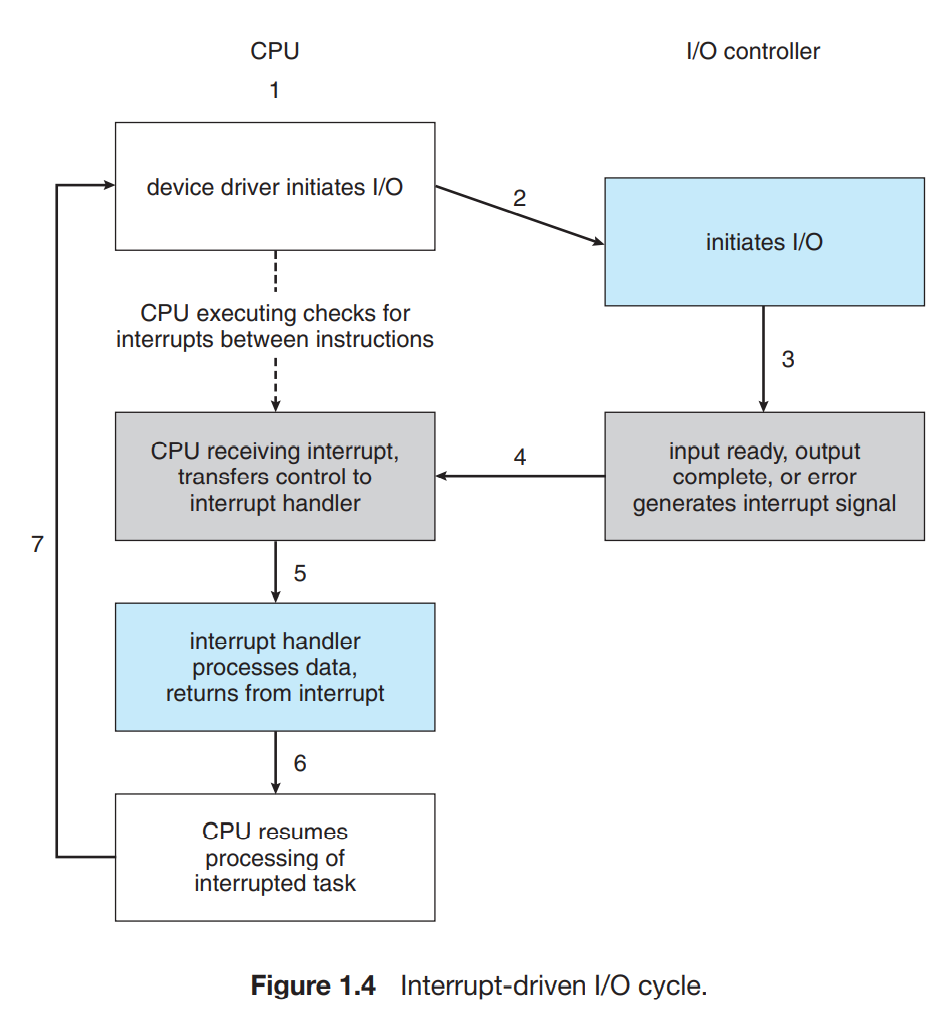
- Hardware may trigger an interrupt at any time by sending a signal to the cpu, usually via system bus
- When interrupted, the cpu immediately switches to the interrupting program, when that program is done, the cpu switches back to the interrupted program
- Interrupt mechanism are different in different computers, but
interrupt must transfer control to the appropriate interrupt service
routine
- One way is to use a generic routine to examine the interrupt information, this routine calls the interrupt-specific handler, but this approach does not satisfy the speed requirement
- Another way is to use a table of pointers (called interrupt vector) stored in low memory to hold the addresses of the interrupt service routines for various devices
- Implementation via interrupt vector
- CPU hardware has a wire called the interrupt-request line that the cpu senses after executing every instruction
- When cpu detects a controller has asserted a signal on the interrupt-request line, it jumps to the interrupt-handler routine by using the interrupt number as an index into the interrupt vector (device controller/hardware faults raises an interrupt, the cpu catches the interrupt and dispatches it to the interrupt handler)
- The interrupt handler performs all related work and return the cpu to the execution state prior to the interrupt (interrupt handler clears the interrupt)
- The interrupt mechanism also implements a system of interrupt priority level
- Storage structure
- Memory
- Main memory (Random access memory, RAM), commonly ram is implemented using a semiconductor technology called dynamic random access memory (DRAM). RAM is volatile, it loses all its content when power is turned off
- Other types of memory: EEPROM (electrically erasable programmable read-only memory), ROM. Bootstrap is resides in EEPROM, because EEPROM is non-volatile
- All memory provides an array of bytes, each byte has its own
address, cpu uses
laod/storeto interact with memory
- Secondary storage
- Be able to hold large quantities of data permanently
- Common secondary storage devices: hard-disk drives(HDDs), nonvolatile memory (NVM) devices
- Tertiary storage: magnetic tape, optical disk, blue-ray
- Nonvolatile storage: mechanical or electrical storage
- Memory
- I/O structure
- Interrupt-driven I/O is fine for moving small amounts of data, but can produce high overhead when used for bulk data movement
- Direct memory access(DMA) is used to transfer entire block of data between device and main memory
- Computer system architecture Ch 1.3
- Single processor (a processor is a physical chip that contains one ore more cpu) system: one CPU with a single processing core. Core is the component that executes instructions and registers for storing data locally
- There are also special-purpose processors: device-specific processors, run a limited instruction set, do not run processes
- Multiprocessor system
- Advantages
- Increased throughput: if N processors, the speed-up ration is less than N
- Economy of scale: average cost is reduced, multiprocessor system can share power supplies, peripherals, mass storage
- Increased reliability: if properly distributed, then failure of one processor will not halt the system
- The most common multiprocessor systems use symmetric multiprocessing (SMP), each peer cpu processor performs all tasks. Each processor has its own cpu, set of registers and local cache, all processors share physical memory over the system bus
- Multicore system: multiple computing cores reside on a single chip, each core has its own cpu and L1 cache, but L2 cache is shared among cores. This is faster than traditional multiprocessor system, because on-chip communication is faster than between-chip communication
- Advantages
- Clustered system
- A clustered system is composed of two or more individual systems
- Clustering is usually used to provide high-availability service, high availability provides increased reliability (graceful degradation/ fault tolerant)
- Asymmetric clustering: one machine is in hot-standby mode, the other is running the applications
- Symmetric clustering: two or more hosts are running applications and are monitoring each other
- Operating system operations Ch 1.4
- Bootstrap program is in the computer firmware, it loads the os into memory
- Some os services are provided outside the kernel, they are provided by system programs that are loaded into the memory at boot time, thee system programs become system daemons
- Interrupts signal events
- Introduction
- Hardware device controller can raises interrupts
- Trap(exception) is a software-generated interrupt, trap is either caused by an error or by a specific request from a user program that an os service be performed by executing a special operation called a system call
- Multiprogramming and multitasking
- A program in execution is called a process. In multiprogramming, there are multiple processes loaded into the memory
- Multitasking is a logical extension of multiprogramming
- CPU scheduling: determines which process is executed next
- Virtual allows the logical memory be separated from the physical memory
- Dual-mode and multi-mode operation
- We must be able to distinguish between the execution of operating-system code and user-defined code
- User mode, kernel mode (supervisor mode, system mode, privileged mode). Transition between the two modes is made by system call
- A mode bit is added to the hardware of the computer to indicate the current mode: kernel(0) or user(1)
- The concept of modes can be extended beyond two modes
- Timer
- Timer is used to ensure that the os maintains the control over the cpu, and a user program always returns control to the os (not stuck in an infinite loop, or fail to invoke system call)
- A timer can be set to interrupt the computer after a specified period, the period can be fixed, or variable (achieved by a fixed-rate clock and a counter, when counter decreases to 0, an interrupt occurs)
- Introduction
- Resource management Ch 1.5
- Process management
- Creating and deleting both user and system processes
- Scheduling processes and threads on the cpus
- Suspending and resuming processes
- Providing mechanisms for process synchronization
- Providing mechanisms for process communication
- Memory management
- Keeping track of which parts of memory are being used and which process is using them
- Allocating and deallocating memory space as needed
- Deciding which processes and data to move into and out of memory
- File system management
- Creating and deleting files
- Creating and deleting directories to organize files
- Supporting primitives for manipulating files and directories
- Mapping files onto mass storage
- Backing up files on stable storage media
- Mass storage management
- Mounting and unmounting
- Free space management
- Storage allocation
- Disk scheduling
- Partitioning
- Protection
- Process management
- What does os do Ch 1.1
- Operating system structures
- Operating system services Ch 2.1
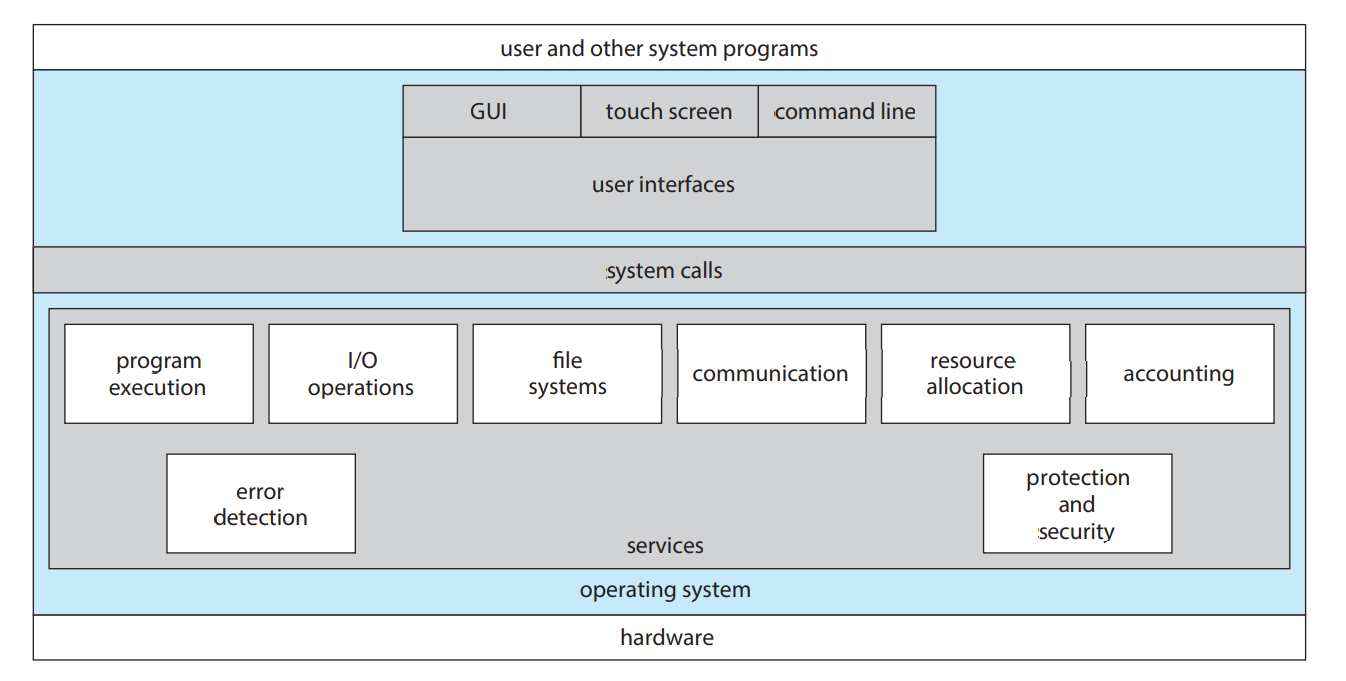
- User interface (UI): graphical user interface(GUI), touch-screen interface, command-line interface(CLI)
- I/O operations: users usually cannot control I/O devices directly
- File-system manipulation
- Communication: inter-process communication implemented via shared memory or message passing
- Error detection
- Resource allocation: allocate resources among different processes
- Logging: record events
- Protection and security
- User and os interface Ch 2.2
- Command-line interface/ command interpreter (shell)
- Main functionality: get and execute the next user-specified command
- Two ways to interpret the commands:
- The command interpreter contains the code to execute the command
- The commands are implemented through system programs, the command interpreter loads commands into memory and execute them
- Command-line interface/ command interpreter (shell)
- System calls Ch 2.3
- System calls provide an interface to the services made available by an operating system
- Application programming interface (API)
- API specifies a set of functions that are available to an application programmer, including the parameters that are passed to each function and the return values the programmer can expect
- Three most common APIs: Windows API for Windows systems, the POSIX API for POSIX-based systems (virtually all versions of UNIX, Linux, and macOS), Java API for Java virtual machines
- The function that makes up an API typically invoke the actual system calls on behalf of the application programmer
- Why use API instead of system calls directly:
- Portability: program can run on any machine that supports the same set of API
- Easy to use: APIs are much simpler and easier to use than system calls
- Types of system calls
- Process control
- Operations: create/terminate process, load/execute program, get/set process attribute, wait/signal event, allocate/free memory
- Windows/Unix system calls:
CreateProcess()/fork(),ExitProcess()/exit(),WaitForSingleObject()/wait()
- File management
- Operations: create/delete file, open/close file, read/write/reposition file, get/set file attribute
- Windows/Unix system calls:
CreateFile()/open(),ReadFile()/read(),WriteFile()/write(),CloseHandle()/close()
- Device management
- Operations: request/release device, read/write/reposition device, get/set device attribute, logically attach/detach device
- Windows/Unix system calls:
SetConsoleMode()/ioctl(),ReadConsole()/read(),WriteConsole()/write()
- Information maintenance
- Operations: get/set time or date, get/set system data, get/set process file, set/set process, file or device attributes
- Windows/Unix system calls:
GetCurrentProcessID()/getpid(),SetTimer()/alarm(),Sleep()/sleep()
- Communications
- Message-passing model: server and client communicates through established connection(use hostname and process name to establish connection)
- Shared-memory model: processes use shared memory (which is not allowed by os in common situations) to exchange data, the type and format of data is determined by processes themselves, not by the os
- Operations: create/delete communication connection, send/receive messages, transfer status information, attach/detach remove devices
- Windows/Unix system calls:
CreatePipe()/pipe(),CreateFileMapping()/shm_open(),MapViewOfFile()/mmap()
- Protection
- Operations: get/set file permissions
- Windows/Unix system calls:
SetFileSecurity()/chmod(),InitializeSecurityDescriptor()/umask(),SetSecurityDescriptorGroup()/shown()
- Process control
- Operating system services Ch 2.1
- Processes
- Process concept Ch 3.1
- Contemporary computer systems allow multiple programs to be loaded into memory and executed concurrently, this requires firm control and compartmentalization of the various programs, these needs results the notation of a process, which is a program in execution.
- A process is the unit of work in modern computer systems
- The status of a process is represented by the value of the program counter and the contents of the processor's registers
- The memory layout of a process is divided into:
- Text section: the executable code, fixed size
- Data section: global variables, fixed size
- Heap section: memory that is dynamically allocated during program run time, variable size
- Stack section: temporary data storage when invoking functions, variable size, contains activation records (when a function is called, an activation record containing function parameters, local variables and the return address is pushed onto the stack)
- Process state
- New: the process is being created
- Running: instructions are being executed
- Waiting: the process is waiting for some event to occur
- Ready: the process is waiting to be assigned to a processor
- Terminated: the process has finished execution
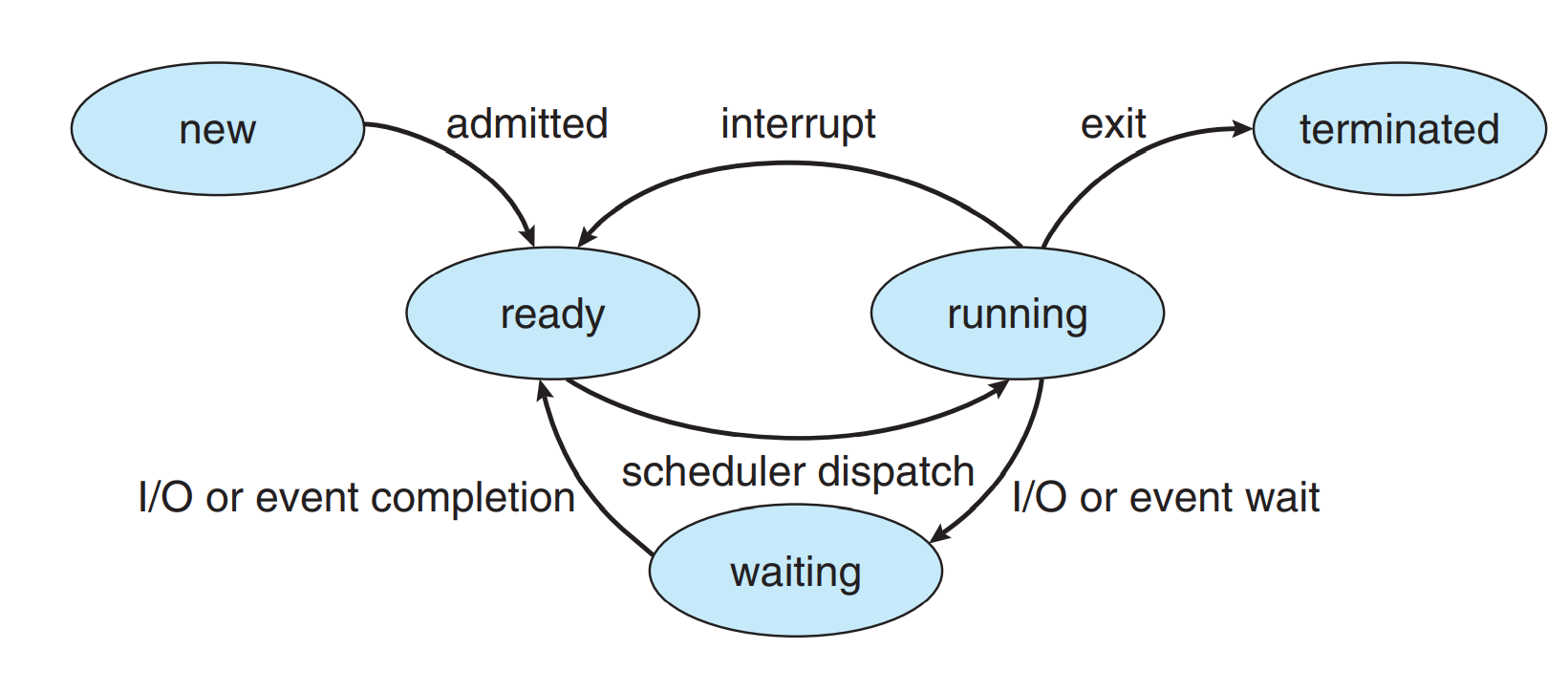
- Process control block
- Each process is represented in the os by a process control block (PCB, also called task control block)
- Contained information
- Process state
- Process id
- Program counter
- CPU registers
- CPU scheduling information
- Memory management information
- Accounting information
- I/O status information
- Threads: PCB can be extended to be compatible with multiple threads
- Process scheduling Ch 3.2
- Goals
- Goal of multiprogramming: maximize cpu utilization
- Goal of time sharing: switch cpu among processes fo that users can interact with each program while it is running
- Each cpu core can run one process at a time, the process scheduler selects an available process for program execution on a core
- Degree of multiprogramming: the number of processes currently in memory
- Bounds
- CPU-bound process: a process that spends more of its time doing computations than doing I/O
- I/O-bound process: a process that spends more of its time doing I/O than doing computations
- Scheduling queues
- Ready queue: processes that are ready and waiting to execute on a core
- Wait queue: process that are waiting for a certain event to occur,
there are different kinds of wait queues
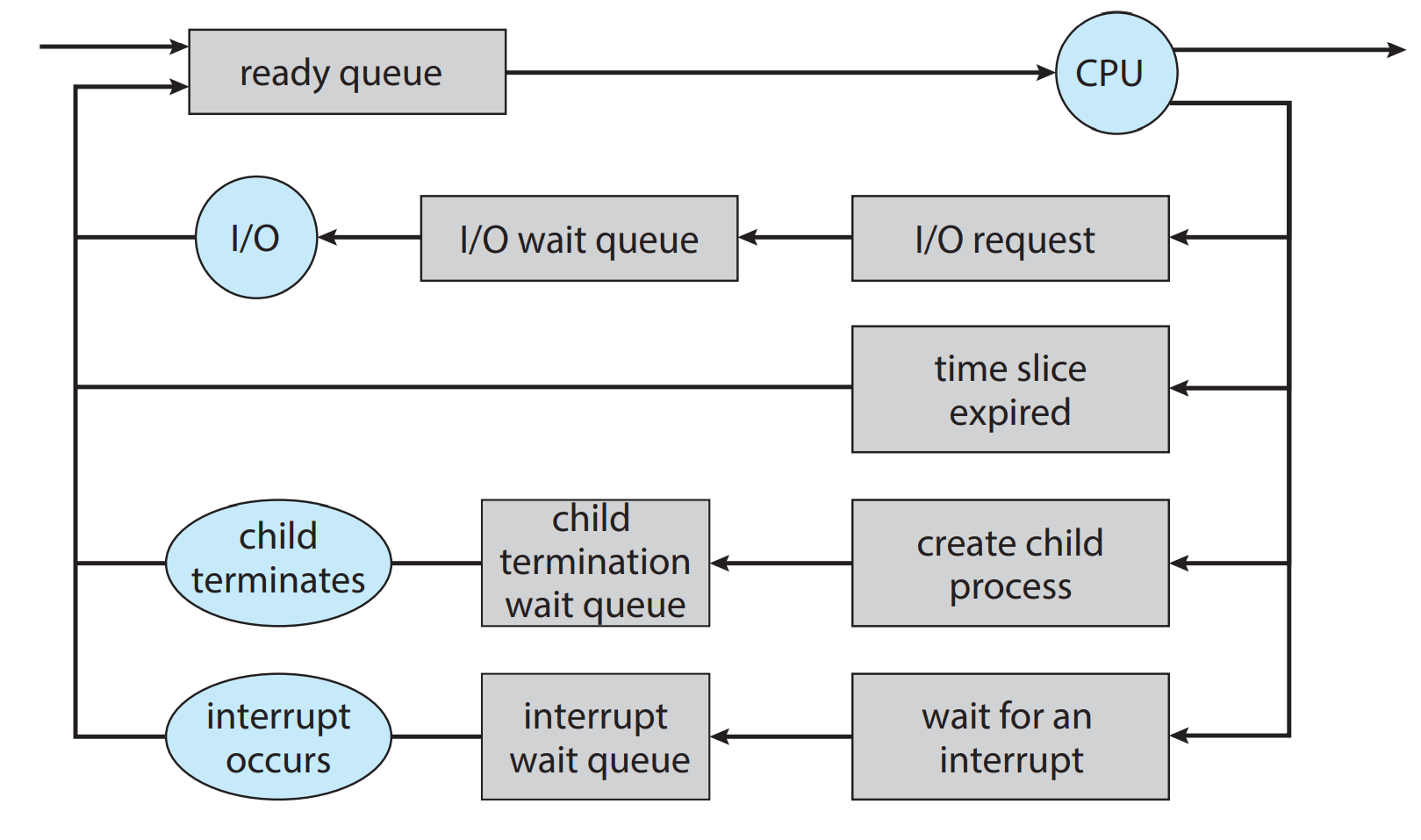
- Context switch:
- Switching the cpu core to another process requires saving the current state of the cpu core to process PCB and restoring the state of a different process from its PCB
- Context switch time is pure overhead, because the system does no
useful work while switching
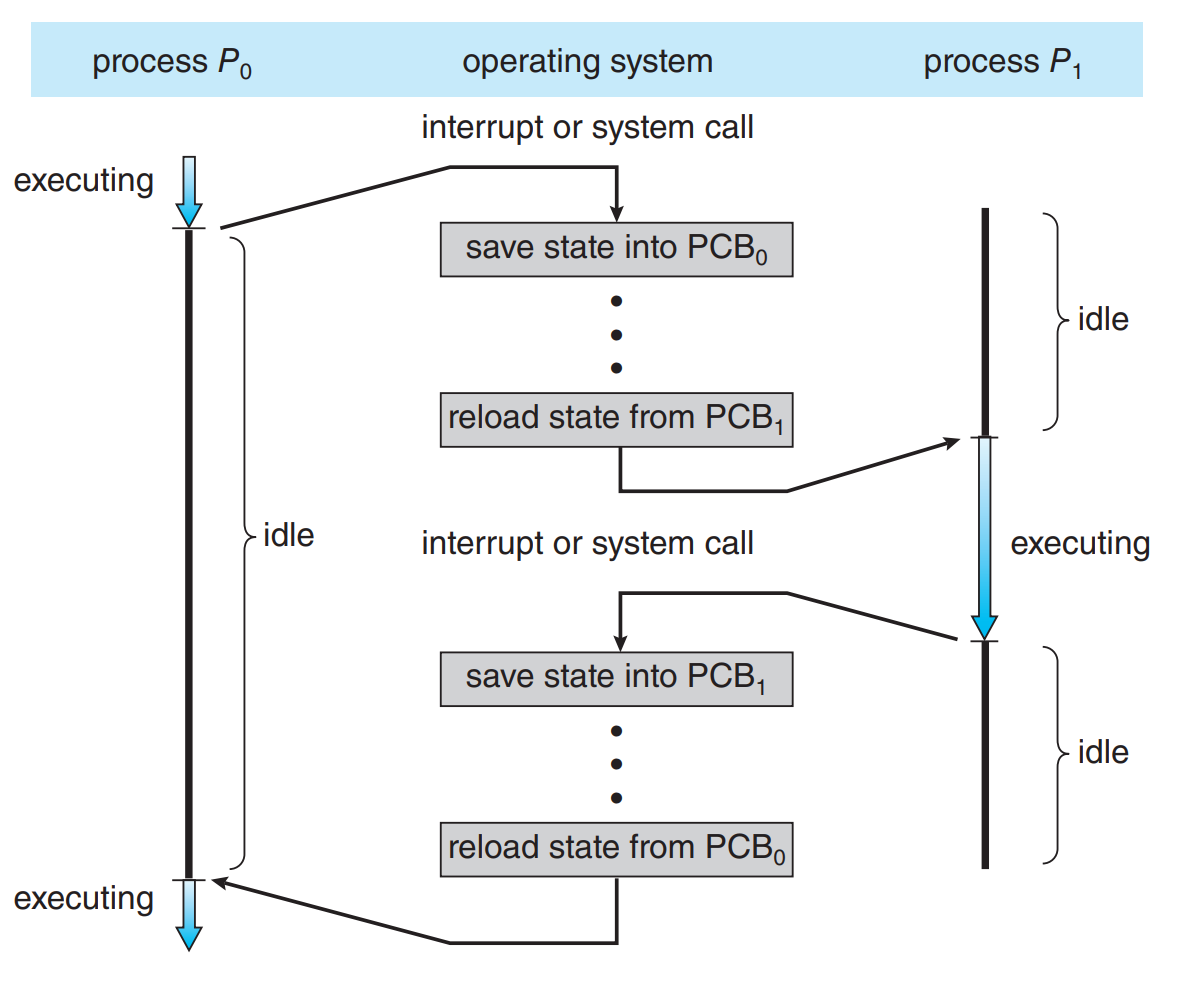
- Goals
- Operations on processes Ch 3.3
- Process creation
- Parent processes create child processes, the result is a tree of processes
- Most operating systems identify processes according to a unique process identifier (pid)
- When a process creates a child process, that child process will need certain resources (cpu time, memory files, I/O devices) to accomplish its task
- Execution possibilities:
- The parent continues to execute concurrently with its children
- The parent waits until some or all of its children have terminated
- Address space possibilities:
- The child process is a duplicate of the parent process
- The child process has a new program loaded into it
- Process termination
- When a process terminates, it asks the os to delete it by using the
exit()(exit with a status number:exit(exit_status_num)) system call - The process may return a status value to its waiting parent process
- The resources (memory, files, I/O buffers) of the process are de-allocated and reclaimed by the os
- A process can cause the termination of another process via an
appropriate system call. Usually, such a system call cal be invoked only
by the parent of the process that is to be terminated. Reasons for
parent to terminate a child process:
- The child has exceeded its usage of some of the resources that it has been allocated
- The task assigned to the child is no longer required
- The parent is exiting and the operating system does not allow a child to continue if its parent terminates
- Cascading termination: the phenomenon that all child processes are terminated when the parent process terminates
- A parent process can use the
wait()system call to wait for the termination of a child process - When a process is terminated, is resources are de-allocated by its entry is still on the process table (the process table is a data structure maintained by the os to facilitate context switching and scheduling, each entry in the process table is a pointer to a specific process control block).
- Zombie process: if a process is terminated by its parent has not yet
called wait, then the process is called a zombie process. Only when the
parent process calls
wait(), the record of a zombie process is removed from the process table - Orphan process: if a process is running but its parent process has terminated, then the process is called an orphan process. Traditional Unix system assigns a new parent process to the orphan process
- When a process terminates, it asks the os to delete it by using the
- Process creation
- Inter-process communication (IPC) Ch 3.4
- If a process doe not share data with any other processes executing in the system, then it's independent. Otherwise a process is cooperating
- Why we need inter-process communication
- Information sharing
- Computation speedup
- Modularity
- IPC models:
- Shared memory: a region of memory is shared by cooperating
processes, processes can exchange information by reading and writing
data to the shared region
- Faster: system call only occurs when creating the shared memory region
- If two processes write in the same location, there may be conflicts
- Message passing: communication is achieved by message exchanged
between the cooperating processes
- Easier to implement in a distributed system
- Useful for exchanging smaller amounts of data, because no conflicts need to be avoided
- Shared memory: a region of memory is shared by cooperating
processes, processes can exchange information by reading and writing
data to the shared region
- IPC in shared memory systems
- Typically, os does not allow one process to access the memory of another process, in order to create a shared memory, this restriction needs to be removed
- Producer and consumer with shared memory
- Unbounded buffer: the buffer capacity is infinite
- Bounded buffer: the producer must wait when the buffer is full, the consumer must wait when the buffer is empty
- IPC in message passing systems
- Message passing facility allows processes to communicate and to synchronize their actions
- Operations
send(message): message size can be fixed or variablereceive(message): message size can be fixed or variable
- A link is needed for message passing
- Direct or indirect communication
- Direct communication
send(P, message): send a message to process Preceive(Q, message): receive a message from process Q, this is symmetry addressing- A link is automatically created between two processes
receive(id, message): receive a message from any process, the id is the process_id, this is asymmetry addressing
- Indirect communication
send(A, message): send a message to mailbox/port Areceive(A, message): receive a message from mailbox/port A- A link is established if processes have a shared mailbox/port, then the link may be associated with more than two processes
- Direct communication
- Synchronous or asynchronous communication
- Message sending can be blocking/synchronous or non-blocking/asynchronous
- Blocking send, non-blocking send, blocking receive, non-blocking receive
- Automatic or explicit buffering
- The messages exchanged by communicating processes reside in a temporary queue
- Queue capacity
- Zero capacity: the sender must block until the recipient receives the message
- Bounded capacity: the sender must block when the queue is full
- Unbounded capacity: the sender is never blocked
- Communication in client server system
- Apart from the shared memory and message passing, the client-server systems can also use two other strategies for communication: sockets and remote procedure calls (RPCs)
- Sockets
- A socket is defined as an endpoint for communication, a pair of processes communicating over a network employs a pair of sockets
- A socket is identified by an IP address concatenated with a port number
- Generally, sockets use a client-serve architecture: the server waits for incoming client requests by listening to a specified port, once a request is received, the server accepts a connection from the client socket to complete the connection. App ports below 1024 are considered well known and are used to implement standard services
- When a client initiates a request for a connection, it's assigned a port by its host computer, the port has some arbitrary number greater than 1024
- All connections are unique
- Java sockets
- Connection-oriented sockets (TCP) implemented with the
Socketclass - Connectionless sockets (UDP) use the
DatagramSocketclass - The
MulticastSocketclass is a subclass of theDatagramSocketclass: a multicast socket allows data to be set to multiple recipients
- Connection-oriented sockets (TCP) implemented with the
- Remote procedure calls
- RPC paradigm is one of the most common forms of remote service and it's usually based upon the IPC mechanism with message-based communication scheme
- A port in RPC is simply a number included at the start of a message packet. A system normally has one network address, but it can have many ports
- RPC allows a client to invoke a procedure on a remote host as it would invoke a procedure locally, the RPC system hides the details
- RPCs can fail due to common network errors, so RPC uses the exactly once semantics for calls
- Process concept Ch 3.1
- Threads & Concurrency
- Overview Ch 4.1
- Benefits of multi-threaded programming
- Responsiveness: a program can continue running even if part of it is blocked or is performing a lengthy operation
- Resource sharing: threads share the memory and the resources of the process to which they belong by default, sharing resources among processes is costly
- Economy: it is more economical to create and context-switch threads
- Scalability: for multiprocessor architecture, threads may be running in parallel on different processing cores
- Benefits of multi-threaded programming
- Multi-core programming Ch 4.2
- Concurrency and parallelism
- A concurrent system supports more than one task by allowing all the tasks to make progress
- A parallel system can perform more than one task simultaneously. It is possible to have concurrency without parallelism
- Multi-core programming challenges
- Identifying tasks: tasks are independent
- Balance: tasks perform equal work of equal value
- Data splitting: data should be divided to run on separate cores
- Data dependency: data should be examined for dependencies between two or more tasks
- Testing and debugging: testing and debugging concurrent programs is more difficult
- Types of parallelism
- Data parallelism: distribute subsets of the same data across multiple computing cores and performing the same operation on each core
- Task parallelism: distribute tasks across multiple computing cores
- Concurrency and parallelism
- Multi-threading models Ch 4.3
- User threads and kernel threads
- User threads are supported above the kernel and managed without kernel support
- Kernel threads are supported and managed directly by the os
- Multi-threading models measure the relationship between user threads and kernel threads
- Many-to-one model
- Maps many user level threads to one kernel level thread
- Efficient: thread management is done by thread library in user space
- The entire process will block if a thread makes a blocking system call
- Only one thread can access the kernel at a time, multiple threads are unable to run in parallel on multi-core systems
- Very few systems continue to use this model now
- One-t-one model
- Maps each user thread to a kernel thread
- Threads can run in parallel, one blocked thread does not affect other threads
- Each user thread corresponds to a kernel thread, this may burden the performance of a system
- Linux and Windows implements one-to-one model
- Many-to-many model
- Multiplexes many user level threads to a smaller or equal number of kernel threads
- Allows parallelism, the system is efficient
- Difficult to implement in practice
- User threads and kernel threads
- Thread library Ch 4.4
- A thread library provides the programmer with an API for creating and managing threads
- Implementation approaches
- Provide a library in user space with no kernel support: invoking a function in the library results in a local function call in user space and not a system call
- Implement a kernel level library supported directly by the os: invoking a function in the library results in a system call to the kernel
- Main thread libraries
- POSIX Pthreads: can be either a user level library or a kernel level library
- Windows thread library: kernel level library
- Java thread API: allows threads to be created and managed directly in java programs, because in most cases, the JVM is running on top of a host os, the Java thread API is generally implemented using a thread library available on the host system
- Ptrheads
- Pthreads refer to the POSIX standard defining an API for thread creation an synchronization
- It is a specification for thread behavior, not an implementation
- Windows threads
- Similar to the Pthreads
- Java threads
- Thread creation in Java
- Extends the
Threadclass and overwrites therun()method - Implements the
Runnableinterface and overwrites therun()method
- Extends the
- Interrupt
- Call the
join()method on a child thread to that the parent thread waits until the child thread terminates1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(i);
Thread.sleep(1000);
}
}
});
t.start();
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
- Call the
- Thread creation in Java
- Implicit threading Ch 4.5
- Implicit threading: inorder to address the difficulties of handling large amounts of threads and better support the design of concurrent and parallel applications, the creation and management of threading should be transferred from developer to compiler and run-time libraries
- Tread pools
- Idea: create a pool of threads, when there is a request, find one idle thread in the pool and let it service the request. If there is no idle thread, the task is queued until one thread becomes available. Once a thread finishes its task, it returns to the pool and awaits next task
- Benefits
- Servicing a request with an existing thread is faster than creating a new thread
- A pool can limit the number of threads that exist at any give time, this alleviates the burden of os
- Separating the task from the mechanics of creating the task allows user to use different strategies for running the task
- Fork join
- The parent thread creates (forks) one ore more child threads and then waits for the children to terminate and join with it, at which point it can retrieve and combine their results
- OpenMP
- OpenMP is a set of compiler directives as well as an API for programs written in C, C++, or FORTRAN that provides support for parallel programming in shared memory environments
- OpenMP identifies parallel regions as blocks of code that may run in parallel
- OpenMP also allows developer s to choose among several level of parallelism
- Grand central dispatch (GCD)
- GCD is developed by Apple
- It is a combination of a run time library, an API, and language extension that allow developers to identify sections of code to run in parallel
- GCD schedules tasks for run time execution by placing them on a dispatch queue
- Overview Ch 4.1
- CPU Scheduling
- Basic concepts Ch 5.1
- CPU-I/O burst cycle
- Process execution consists of a cycle of cpu execution and I/O wait, processes alternate between these two states
- Process execution begins with a cpu burst, then an I/O burst, then ..., the final cpu burst ends with a system request to terminate execution
- CPU bursts tend to have a large number of short cpu bursts, and a small number of long cpu bursts. An I/O bound program tends to have many short cpu bursts, a cpu bound program might have a few long cpu bursts
- CPU scheduler
- When a cpu is idle, the cpu scheduler selects a process from the processes in memory that are ready to execute and allocates the cpu to that process
- The ready queue is not necessarily a FIFO queue, its structure varies depending on the scheduling algorithm
- Preemptive and non-preemptive scheduling
- Four circumstances where cpu scheduling decision may take place
- A process switches from the running state to the waiting state
- A process switches from the running state to the ready state
- A process switches from the waiting state to the ready state
- A process terminates
- A non-preemptive(cooperative) scheduling algorithm picks a process to turn and then just lets it run until it blocks or voluntarily releases the cpu
- A preemptive scheduling algorithm picks a process and lets it run for a maximum of some fixed time. If it is still running at the end of the time interval, it is suspended and the scheduler picks another process to run
- Preemptive scheduling can result in race condition
- Preemption also affects the design of the os kernel. If a process is preempted during a system call in which some state of the kernel is modified, then chaos ensues. A non-preemptive will wait for a system call to complete
- Four circumstances where cpu scheduling decision may take place
- CPU-I/O burst cycle
- Scheduling criteria Ch 5.2
- CPU utilization
- We should maximize the cpu utilization
- In a real system, the cpu utilization should range from 40% (lightly loaded system) to 90% (heavily loaded system)
- CPU utilization
- Throughput
- We should maximize the throughput
- Throughput is the amount of processes that are completed per time unit
- Turnaround time
- We should minimize the turnaround time
- Turnaround time: the interval from the time of submission of a process to the time of completion of the process
- Turnaround time is the sum of the periods spend waiting in the ready queue, executing on the cpu and doing I/O
- Waiting time
- We should minimize the waiting time
- The scheduling algorithm does not affect the amount of time during which a process executes or does I/O, it affects only the amount of time that a process spends waiting in the ready queue
- Waiting time is the sum of the periods spend waiting in the ready queue
- Response time
- We should minimize the response time
- Response time is the time from the submission of a request until the first response is produced (the time it takes to start responding, not the time it takes to output the response)
- This measure is more appropriate for an interactive system
- Basic concepts Ch 5.1
- Scheduling algorithms Ch 5.3
- We assume there is a single cpu with a single processing core, thus the system is capable of only running one process at a time
- Use Gantt chart to visualize the scheduling algorithm
- First-come first-serve (FCFS)
- Idea: the process that requests the cpu first is allocated the cpu first
- FCFS is a non-preemptive scheduling algorithm
- FCFS can be implemented using a FIFO queue (actually the scheduling queue can just be the ready queue)
- Convoy effect: the whole system is slow down due to a few slower processes (if the process with the longest cpu burst arrives at first, then the average turnaround time will be very long)
- FCFS is bad for troublesome for interactive systems
- Shortest-job-first scheduling (SJF)
- Idea: when the cpu is available, the process that has the smallest next cpu burst is allocated to the cpu, if the next cpu burst of multiple processes are the same, FCFS scheduling is used to break the tie
- The SFJ scheduling algorithm is provably optimal, because it gives the minimum average waiting time for a given set of processes
- SJF cannot be implemented at the level of cpu scheduling, because there is no way to know the length of the next cpu burst, instead we can pick the process with the shortest predicted cpu burst
- The next cpu burst is generally predicted using an exponential
average:
- Preemptive SJF: shortest-remaining-time-first scheduling: when a new process comes and the older one is still running, if the next cpu burst of the new process is shorter than the remaining cpu burst of the older one, then the older process is preempted and the new process is allocated to the cpu
- Round-robin scheduling (RR)
- Idea: similar to FCFS with preemption via time quantum (time slice). The ready queue is treated as a circular queue, each process can be executed for an interval of up to 1 time quantum
- The average waiting time for RR is often long
- If the time quantum is very large, then RR is just FCFS. If the time quantum is very small, then there are a large number of context switches. The time quantum should be set so that context switch time is a relative small fraction of the time quantum
- If time quantum increases, the turnaround time does not necessarily decreases
- Priority scheduling
- Idea: a priority is associated with each process, and the cpu is allocated to the process with the highest priority, equal-priority processes are scheduled in FCFS order
- A SJF is simply a priority scheduling algorithm where the priority is the inverse of the next cpu burst
- Priorities can be defined either internally or externally
- Priority scheduling can be either non-preemptive or preemptive
- A major problem with priority scheduling is indefinite blocking, or starvation: a low priority process can wait indefinitely.
- A solution to the problem of indefinite blockage of low-priority processes is aging, which meas gradually increases the priority of processes that wait in the system for a long time
- Another solution is to combine RR and priority scheduling (same priority processes are scheduled in RR)
- Multilevel queue scheduling
- Idea: there are separate queues for each distinct priority, scheduling between queues are priority scheduling, scheduling inside one queue is round-robin
- Processes have a static priority, so they reside in the same queue forever
- Multilevel feedback queue scheduling
- Idea: multilevel queue scheduling + processes can move between queues
- Synchronization Tools
- Background Ch 6.1
- Concurrent or parallel execution can contribute to issues involving the integrity of data shared by several processes
- Race condition: a situation where several processes access and manipulate the same data concurrently and the outcome of the execution depends on the particular order in which the access take place is called race condition
- We use process synchronization to prevent race condition
- The critical section problem Ch 6.2
- Situation: a system consists of n processes
- The critical-section problem is to design a protocol that the processes can use to synchronize their activity so as to cooperatively share data
- Procedure of each process: entry section -> critical section -> remainder section
- Requirements for critical section problems
- Mutual exclusion: if process
- Progress: if no process is executing in its critical section and some processes wish to enter their critical section, then only the processes that are not int the exit section can decide which will enter the critical section next, and this selection cannot be postponed indefinitely
- Bounded waiting: if a processes has made a request to enter its critical section, the its waiting time should be bounded before the request is granted
- Mutual exclusion: if process
- Two general approaches to handle critical sections in os:
- Preemptive kernels
- Processes in the kernel mode cannot be preempted, they will run until it exits the kernel mode, blocks, or voluntarily yields control of the cpu
- Free from race conditions
- Non-preemptive kernels
- More responsive
- More suitable for real-time programming
- Preemptive kernels
- Situation: a system consists of n processes
- Peterson's Solution Ch 6.3
- Peterson's solution is a software-based solution to the critical section problem
- Given the way that modern computer architectures perform
machine-language instructions (such as
LOAD,STORE), there is no guarantee that Peterson's solution works on such architectures - Idea: two processes alternate execution between critical sections and other sections, if one is ready (wishes) to enter its critical, the other process will wait (if one is not ready to, or wishes to enter its critical section, it will skips its turn to enter the critical section)
- Algorithm
- Shared variables
int turn: ifturn == 0, thenturn == 1, thenboolean flag[2]: ifflag[0] == true, thenflag[1] == true, then
- Java implementation
1
2
3
4
5
6
7
8
9
10
11while (true) {
// Entry section
flag[i] = true;
turn = j; // turn = 1 - i
while (flag[j] && turn == j) {
; // Wait
}
// Critical section
flag[i] = false;
// Remainder section
}
- Shared variables
- Proof of mutual exclusion, progress and bounded waiting
- Mutual exclusion
- If
flag[i] == true and (turn == i or flag[j] == false) - If
flag[j] == true and (turn == j or flag[i] == false) - These two conditions cannot happen simultaneously
- If
- Progress:
flag[j] == true and turn == j, then - Bounded waiting: after
flag[j] = false, so
- Mutual exclusion
- Why Peterson's solution may not work: to improve performance, modern
computers may reorder read/write instructions for independent variables
- Example We want Thread to print 100, but if computer reorders the instructions in Thread 2, then Thread 1 will print 1
1
2
3
4
5
6
7
8
9
10//Thread 1
boolean flag = false;
int x = 1;
while (!flag) {
;
}
System.out.println(x);
// Thread 2
int x = 100;
flag = true;
- Example
- Hardware support for synchronization Ch 6.4
- Memory Barriers
- Memory model: how a computer determines what memory guarantees it will provide to an application program is called the memory mode
- Memory model categories:
- Strongly ordered model: a memory modification on one processor is immediately visible to all other processes
- Weakly ordered model: modifications on one processor may not be immediately visible to other processes
- Memory barriers/ fences: computer instructions that can force any
changes in memory to be propagated to all other processors, thereby
ensuring that memory modifications are visible to threads running on
other processors
- An example
1
2
3
4
5
6
7
8
9
10
11//Thread 1
boolean flag = false;
int x = 1;
while (!flag) {
memory_barrier();
}
System.out.println(x);
// Thread 2
int x = 100;
memory_barrier();
flag = true;
- An example
- Hardware instructions
- Modern computer architectures usually provide atomic instructions to test and modify the contents of a variable or swap the contents of variables
test_and_set()and mutual exclusiontest_and_set()1
2
3
4
5boolean testAndSet(boolean flag) {
oldVal = flag;
flag = true;
return oldVal;
}Mutual exclusion with test_and_set
1
2
3
4
5
6
7
8
9
10boolean lock = false;
while (true) {
// Entry section
testAndSet(lock) {
; // Wait here
}
// Critical section
lock = false;
// Remainder section
}
compare_and_swap()and mutual exclusioncompare_and_swap()1
2
3
4
5
6
7int compareAndSwap(int val, int exp, int newVal) {
int tmp = val;
if (val == exp) {
val = newVal;
}
return tmp;
}- Mutual exclusion with compare_and_swap
1
2
3
4
5
6
7
8
9
10int lock = 0;
while (true) {
// Entry section
while (compareAndSwap(val, 0, 1)) {
; // Wait here
}
// Critical section
lock = 0;
// Remainder section
}
- Atomic variables
- Atomic variables: a tool that is based on compare_and_swap and is used to solve the critical section problem
- Most systems that support atomic variables provide special atomic
data structures and functions for accessing and manipulating atomic
variables
- Example
1
2
3
4
5
6void increment(int atomicVar) {
int tmp;
do {
tmp = atomicVar;
} while (tmp != compareAndSwap(v, tmp, tmp + 1));
}
- Example
- Memory Barriers
- Mutex locks Ch 6.5
- Hardware solutions are generally complicated and inaccessible to application programmers, so os usually provides higher-level software solutions
- The simplest solution is mutex lock (mutex is short for mutual exclusion). A process must acquire the lock before entering the critical section and releasing the lock after critical section is completed
- Mutex lock
acquire()1
2
3
4
5
6void acquire(boolean available) {
while (!available) {
; // Wait
}
available = false;
}release()1
2
3void release(boolean available) {
available = true;
}- Mutual exclusion and mutex lock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23boolean available = true;
while (true) {
// Entry section
acquire(available);
// Critical section
release(available);
// Remainder section
}
```
* The above lock is called spin-lock, because the process spins while waiting for the lock to become available
* Advantages: no context switch is required when a process must wait on a lock, context switch may take a considerable time
* Disadvantages: busy waiting, cpu utilization is not optimized
* Semaphores Ch 6.6
* Compared with mutex locks, semaphores can provide more sophisticated ways for processes to synchronize their activities
* Semaphore: a semaphore is an integer variable that, apart from initialization, is accessed only by two standard atomic operations, `wait()`, `signal()`
* `wait()` and `signal()`
```java
void wait(int semaphore) {
while (semaphore <= 0) {
; // Wait
}
semaphore--;
}1
2
3void signal(int semaphore) {
semaphore++;
}
- Counting semaphore and binary semaphore
- Counting semaphore: semaphores that can range over an unrestricted domain
- Binary semaphores: semaphores that can be either 0 or 1
- Semaphore implementation
- The previous
waitandsignalstill use busy waiting - Modified waiting: if wait is called, and the value of semaphore is not positive, then instead of busy waiting, we add the process to a waiting queue associated with the semaphore, and the state of the process is switched from running to waiting, and then the cpu scheduler can pick another process to run
- Implementation
1
2
3
4class Semaphore {
int value;
Queue<Process> waitingQueue;
}1
2
3
4
5
6
7wait(Semaphore s) {
s.value --;
if (s.value < 0) {
s.waitingQueue(thisProcess);
this.Process.sleep();
}
}1
2
3
4
5
6
7signal(Semaphore s) {
s.value++;
if (s.value <= 0) {
Process p = s.waitingQueue.remove();
p.wakeUp();
}
} - When the value of semaphore is negative, its magnitude is the number of processes waiting in the waiting queue of this semaphore
- Semaphore operations should be atomic
- The previous
- Monitors Ch 6.7
- Various errors can happen when programmers misuse semaphores or mutex locks to solve critical section problems, one strategy for handling these errors is to incorporate simple synchronization tools as high-level language constructs, for example, the monitor type.
- A monitor type is an ADT that includes a set of programmer-defined operations that are provided with mutual exclusion within the monitor, the monitor type also declares the variables whose values define the state of an instance of that type, along with the bodies of functions that operate on those variables
- Only one process at a time is active within the monitor
- The monitor type itself is not sufficiently powerful for modeling
some synchronization schemes, so we need to define additional
synchronization mechanisms provided by the condition type. The only
operations that can be invoked on a condition variable are
wait()andsignal()x.wait()with monitor1
2
3
4
5
6
7
8
9
10
11// condition x: binary semaphore x_sem and integer x_count, both initialized to 0
void F() {
x_count ++;
if (next_count > 0) {
signal(next);
} else {
signal(mutex);
}
wait(s_sem);
x_count --;
}x.signal()with monitor
1
2
3
4
5
6if (x_count > 0) {
next_count ++;
signal(x_sem);
wait(next);
next_count--;
}
- Resume processes with a monitor
- When
x.signal()is called on a condition x and there are multiple suspended processes, there are different wats for the monitor to determine which process to wake up - The simplest way is to use a FCFS policy, then the process that has waited for the longest part should be waken up
- In circumstances that FCFS does not work, the monitor can use
conditional wait:
x.signal(cond), where cond is an integer expression that is evaluated when the wait operation is executed. The value of cond, which is called priority number, is stored in the suspended process, and the process with the lowest priority number is waken up
- When
- Background Ch 6.1
- Synchronization examples
- Classic problems of synchronization
- The bounded buffer problem
- The producers and consumers share these data:
int n,Semaphore mutex = 1,Semaphore empty = n,Semaphore full = 0 - The pool consists of n buffers, each capable of holding one item, the mutex binary semaphore provides mutual exclusion for accesses to the buffer pool, the empty and full semaphores count the number of empty and full buffers
- Producer code
1
2
3
4
5
6
7
8while (true) {
// Produce an item
wait(empty);
wait(mutex);
// Add item to the buffer
signal(mutext);
signal(full);
} - Consumer code
1
2
3
4
5
6
7
8while(true) {
wait(full);
wait(mutex);
// Remove an item from buffer
signal(mutex);
signal(empty);
// Consume the item
}
- The producers and consumers share these data:
- Readers-writers problem
- If readers access the database simultaneously, no adverse effects will result. However, if a writer and some other process access the database simultaneously, chaos may ensue
- We require that the writers have exclusive access to the shared database whill writing to the database
- Variations of readers-writers problem
- The first readers-writers problem
- No reader shall be kept waiting if the shared data is opened for reading
- In this variation, writers may starve
- The second readers-writers problem
- No writer in the waiting queue shall be kept waiting longer than absolutely necessary
- In this variation, readers may starve
- The third readers-writers problem
- No thread shall be allowed to be starve
- The operation of obtaining a lock on a shared data will always terminate in a bounded amount of time
- The first readers-writers problem
- Solution to the first readers-writers problem
- Shared variables:
Semaphore rw_mutex = 1: binary semaphore, used to provide mutual exclusion to writers, also used for the first reader to enter and the last reader to exit the critical sectionSemaphore mutex = 1: binary semaphore, ensure mutual exclusion for updating the read_count variableint read_count = 0: count how many readers are accessing the shared data
- Code of a writer process
1
2
3
4
5while (true) {
wait(rw_mutex);
// Perform writing
signal(rw_mutex);
} - Code of a reader process
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17while (true) {
wait(mutex);
read_count ++;
if (read_count == 1) {
// If this is the first reader
wait(rw_mutex);
}
signal(mutex);
// Perform reading
wait(mutex);
read_count--;
if (read_count == 0) {
// If this is the last reader
signal(rw_mutex);
}
signal(mutex;)
}
- Shared variables:
- The dinning-philosophers problem
- A circular table with n philosophers and n chopsticks. Philosophers think individually, when a philosopher is hungry, she picks two nearest chopsticks and eat, when she finishes eating, she releases the two chopsticks
- Semaphore solution
- Represent each chopstick with a binary semaphore, a philosopher grabs a chopstick by executing the wait() operation on that semaphore, and release the chopstick by executing the signal() operation on the semaphore
- This solution can result in a deadlock: all philosophers require the wait operation on the chopsticks on their left side, then require the wait operation on the chopsticks on their right side
- Monitor solution
- Denote the state of a philosopher be eating, thinking, hungry, a philosopher can only be eating if the two neighbors of her are not eating
- The bounded buffer problem
- Synchronization in Java Ch 7.4
- Every object in Java has associated with it a single lock
- You can use synchronized keyword in the method signature to indicate the method is synchronized, calling synchronized method requires owning the lock for the object
- If one synchronized method requires the lock, but the lock is owned by another thread, then calling method blocks and is placed in the entry set for the object's lock. The entry set represents the set of threads waiting for the lock to become available
- If the lock is released, but the entry set of the object is not empty, then JVM arbitrarily picks one thread from the entry set to own the lock
- Each object also has a wait set, if a thread enters a synchronized method but is unable to continue because some condition has not been met, then the thread releases the lock, the state of the thread is changed to blocked, and the thread is placed in the wait set of the object
- Reentrant lock
- A ReentrantLock is owned by a single thread and is used to provide mutually exclusive access to a shared resource, and it can provide additional features, such as setting a fairness parameter, which favors granting the lock to the longest-waiting thread
- A thread acquires a ReentrantLock lock by invoking its
lock()method. If the lock is available or the thread already owns the lock, lock method assigns the invoking thread lock ownership and returns control, if the lock is not available, the invoking thread blocks until it is ultimately assigned the lock when the lock owner invokesunlock()method - ReentrantLock and critical section
1
2
3
4
5
6
7Lock key = new ReentrantLock();
key.lock();
try {
// Critical section
} finally {
key.unlock();
}
- Semaphore
- Java also provides a counting semaphore
- Constructor:
Semaphore(int value) - Semaphore and critical section
1
2
3
4
5
6
7
8
9Semaphores sem = new Semaphore(1);
try {
sem.acquire();
// Critical section
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
sem.release();
}
- Condition variables
- Condition variables provide functionally similar to the
wait()andnotify()methods - Create a condition
1
2Lock key = new ReentrantLock();
Condition condVar = key.newCondition(); - Condition example
1
2
3
4
5
6
7
8
9
10
11
12
13
14Lock key = new ReentrantLock();
Condition condVar = key.newCondition();
key.lock();
try {
if (conditionNotMet) { // User-defined boolean condition
condVar.await();
}
// Do some work
condVar.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
- Condition variables provide functionally similar to the
- Classic problems of synchronization
- Deadlocks
- Introduction
- In a multiprogramming environment, several threads may compete for a finite number of resources. A thread request resources, if the resources are not available, the thread enters a waiting state
- Sometimes, a waiting thread can never change state, because the resources it has requested are held by other waiting threads. This situation is called a deadlock
- Definition of deadlock: every process in a set of processes is waiting for an even that can be caused only by another process in the set
- System model Ch 8.1
- A system consists of a finite number of resources (CPU cycles, files, I/O devices, etc.) to be distributed among a number of competing threads
- A thread may utilize a resource in only the following sequence: request, use, release
- Deadlock in multithreaded applications Ch 8.2
- An deadlock example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Thread A
public void work1() {
lock1.lock();
// If there is context switch after this line, then deadlock will occur
lock2.lock();
// Do some work
lock2.unlock();
lock1.unlock();
}
// Thread B
public void work1() {
lock2.lock();
lock1.lock();
// Do some work
lock1.unlock();
lock2.unlock();
} - Livelock
- Livelock is another kind of liveness failure, similar to deadlock
- Deadlock prevents threads from proceeding because when each thread in a set is blocked waiting for an event that can be caused only by another thread in the set
- Live lock prevents threads from proceeding because when threads continuously attempt an action that fails
- An deadlock example
- Deadlock characterization Ch 8.3
- Necessary conditions (no sufficient conditions)
- Mutual exclusion: at least one resource must be held in a non-sharable node, if another thread requests that resource, the requesting thread must be delayed until the resource has been released
- Hold and wait: a thread must be holding at least one resource and waiting to acquire additional resources that are currently being held by other threads
- No preemption: resources cannot be preempted
- Circular wait: a set
- Resource allocation graph
- A system resource allocation graph can describe more precisely deadlocks
- Vertices:
- Edges: directed edge
- Example
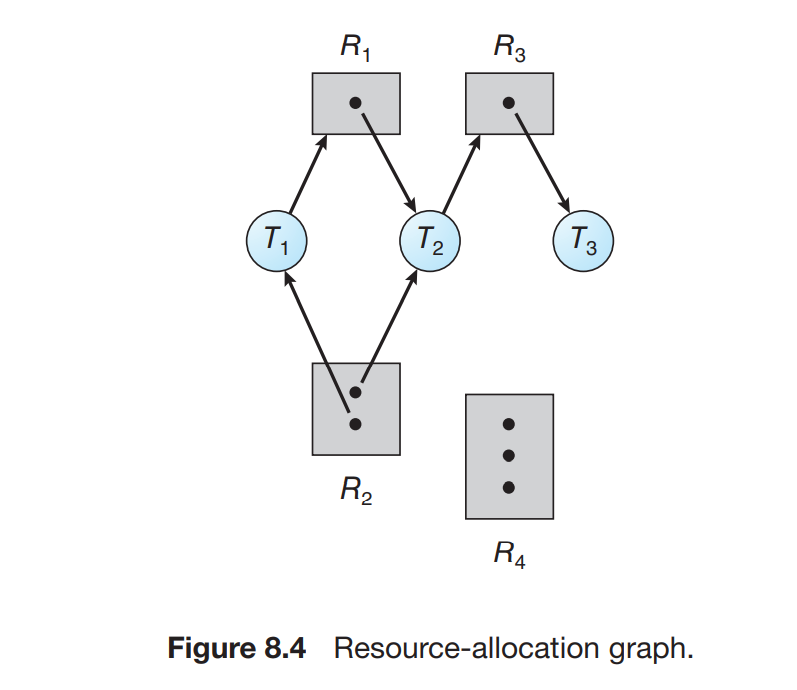
- Observations
- If there is no cycle in the resource allocation graph, then there is no deadlock
- If there is a cycle, then the system may be in the deadlock state
- If there is a cycle (circular waiting), each resource type has one instance, then there must be a deadlock
- Necessary conditions (no sufficient conditions)
- Methods for handling deadlocks Ch 8.4
- Three ways to deal with the deadlock problem
- Ignore the problem, pretend the deadlocks do not exist
- This is adopted by most OS (including Linux and Windows), then it's up to the developers to handle deadlocks, typically using approaches outlined in the second solution
- Dealing with deadlocks are costly, and deadlocks generally happen infrequently
- Use a protocol to prevent or avoid deadlocks, then the system never
enters a deadlock state
- Deadlock Prevention: provides a set of methods to ensure that at least one of the necessary conditions cannot hold, this approach constrains how requests for some resources can be made
- Avoidance: require that the os be given additional information in advance concerning which resources a thread will request and use during its lifetime. With the additional information, the os can decide for each request whether or not the thread should wait
- Allow the system to enter a deadlock state, detect it, and recover.
Some databases adopt this approach
- Use deadlock detection algorithm to check if deadlocks occur, use recovery algorithm to recover from deadlocks
- Ignore the problem, pretend the deadlocks do not exist
- Three ways to deal with the deadlock problem
- Deadlock Prevention Ch 8.5
- Mutual exclusion
- This condition must be hold
- Shareable resources do not require mutually exclusive access and cannot be involved in a deadlock
- Shareable resource example: read-only files
- Non-shareable resources: mutex lock
- Hold and wait
- To break this condition, we require that whenever a thread requests a resource, it does not hold any other resources
- Approach 1: require each thread to request and be allocated all its resources before it begins execution
- Approach 2: a thread can request resources only when it has none (it must release all the resources that it is currently allocated before it can request additional resources)
- Disadvantages of both the approaches
- Resource utilization may be low: resources may be allocated but unused for a long period, for example, a long process with a a very short critical session requesting a mutex lock
- Starvation is possible, a thread that requests several popular resources may have to wait indefinitely
- No preemption
- Approach 1: if a thread is holding some resources and request another resources that cannot be immediately allocated to it, then all resources the thread is currently holding are preempted
- Approach 2: if a thread requests some resources, if there is available resources, we allocate them to the requesting thread. If there is no available resources, but there are some waiting threads holding the desired resources, we preempt the waiting threads and allocate the desired resources to the requesting thread. If both conditions do not hold, we let the thread wait, and all its current resources can be preempted
- Circular wait
- The above approaches of breaking the deadlock conditions are impractical, but there is a practical solution to break the circular wait condition
- Approach: impose a total ordering of resource types and require each thread requests resources in an increasing order of enumeration
- Implementation of this approach
- Resource set
- Requirement 1: initially each thread can request an instance of
resource,
- Requirement 2: if a thread requests an instance of resource
- Resource set
- Proof of correctness: suppose there is circular wait:
- Developing an ordering itself does not prevent deadlock, it's up to developers to write programs that follow the ordering
- Mutual exclusion
- Deadlock avoidance Ch 8.6
- The simplest and most useful model requires that each thread declare the maximum number of resources of each type that it may need
- Resource allocation state: the number of available and allocated resources and the maximum demands of the threads. A deadlock avoidance algorithm dynamically examines the resource allocation state to ensure that a circular wait condition can never exist
- Safe state
- A state is safe if the system can allocate resources to each thread in some order (construct a safe sequence) and still avoid a deadlock
- In a safe state, there are no deadlocks. In an unsafe state, there may be deadlocks
- The avoidance algorithm is constructed so that the system is always in the safe state
- Resource allocation graph algorithm
- If there is only one instance of each resource type, then we can use the resource allocation graph algorithm in deadlock avoidance
- If granting resources to a thread results in a cycle in the resource allocation graph, then the resources should no be allocated.
- Checking whether there is a cycle in a graph takes
- Banker's algorithm
- It can handle resources with multiple instances, although it's less
efficient than the resource allocation graph algorithm
- Terminology
- Available vector: a vector of length m,
available[i] = kindicates there are k instances of resources available for type i
- Max matrix: an n * m matrix defines the maximum demand of each
thread,
max[i][j] = kindicates thread i may request at most k instances of resource type j - Allocation matrix: an n * m matrix defines the number of resources
of each type currently allocated to each thread,
allocation[i][j] = kindicates thread i has k instances of resource type j - Need matrix: an n * m matrix indicates the remaining resource need
of each thread,
need[i][j] = kindicates thread i needs additional k instances of resource type j. Noticeneed[i][j] = max[i][j] - allocation[i][j]
- Safety algorithm
- Let
workandfinishbe vectors of length m and n. Initializework = available, andfinish[i] = falsefor all i - Find an index i such that
finish[i] = falseandneed[i] <= work. If no such i exists, go to step 4 work = work + alloc[i],finish[i] = true. Go to step 2- If
finish[i] = truefor all i, then the system is in a safe state
- Let
- Resource request algorithm
- If
request[i] <= need[i], go to step 2. Otherwise, the thread has exceeded its maximum claim, raises an error - If
request[i] <= available, go to step 3. Otherwise, available = available - request[i],alloc[i] = alloc[i] + request[i],need[i] = need[i] = request[i]
- If
- It can handle resources with multiple instances, although it's less
efficient than the resource allocation graph algorithm
- Deadlock detection Ch 8.7
- Single instance of each resource type
- Use a wait-for graph, which is a variant of the resource allocation graph, to detect deadlocks
- An edge
- The system needs to maintain the wait-for graph, and periodically
check whether there is a cycle in the wait-for graph, this is an
- Several instances of a resource type
- The detection algorithm is similar to the banker's algorithm
- Terminology
- Available: a vector of length m indicates the number of available resources of each type
- Allocation: an n * m matrix defines the number of resources of each type currently allocated to each thread
- Request: an n * m matrix indicates the current request of each thread
- Detection algorithm
- Let
wordandfinishbe vectors of length m and n. Initializework = available, andfinish[i] = falseifallocation[i] != 0, otherwisefinish[i] = true - Find an index i such that
finish[i] = falseandrequest[i] <= work. If not such i exists, go to step 4 work = work + allocation[i],finish[i] = true. Go to step 2- If
finish[i] = falsefor some i, then the system is in a deadlocked state. Moreover, iffinish[i] = false, then thread
- Let
- Detection algorithm usage
- If deadlock occurs frequently, then the detection algorithm should be invoked frequently
- Ideally, we can invoke a deadlock detection algorithm whenever the request of a thread cannot be granted immediately, but such detection will incur considerable overhead in computation time. A less expensive alternative is simply to invoke the algorithm at defined intervals
- Single instance of each resource type
- Recovery from deadlock Ch 8.8
- If a deadlock is detected, several alternatives are available:
- Inform the operator that a deadlock has occurred and let the operator to deal with the deadlock manually
- Let the system recover from the deadlock automatically
- Abort one or more threads to break the circular wait condition
- Preempt some resources from one or more of the deadlocked threads
- Process and thread termination
- Approach 1: abort all deadlocked processes, the system reclaims all
resources allocated to the terminated processes
- This method is expensive
- Aborting a process may not be easy (the process may be updating a file, the process may be holding a mutex lock and updating a shared data, etc.)
- Approach 2: abort one process at a time until the deadlock cycle is
eliminated, resources of the aborted processes are reclaimed by the
system
- This method incurs considerable overhead, since a deadlock detection algorithm should be invoked to determine whether any processes are still deadlocked
- We must determine which deadlocked process should be terminated, the determination policy should be such that the termination incurs minimal cost
- Approach 1: abort all deadlocked processes, the system reclaims all
resources allocated to the terminated processes
- Resource preemption
- We successively preempt some resources from processes and give these resources to other processes until the deadlock cycle is broken
- Issues to be addressed
- Select a victim: select which resources and which processes should be preempted, minimal cost should be incurred
- Rollback: if some needed resources are preempted from a process, obviously it cannot proceed with its normal execution, we need to rollback the process to some safe state and restart it from there. Since it is hard to determine what a safe state is, we can simply abort the process and restart it
- Starvation: we must ensure the resources will not always be preempted from the same process, which means a process can be picked as a victim only a finite number of times to prevent starvation
- If a deadlock is detected, several alternatives are available:
- Introduction
- Main memory
- Background Ch 9.1
- Main memory and the registers built into each processing core are the only general purpose storage that the CPU can access directly
- Basic hardware
- We need to make sure that each process has a separate memory space.
Two registers are used to limit the range of the process memory
- The basic register: holds the smallest legal physical memory address
- The limit register: holds the size of range
- The process memory range is [basic, basic + limit] (both inclusive)
- Protection of memory is accomplished by having the CPU hardware compare every address generated in user mode with the registers. Any attempt by a program executing in user mode to access OS memory or other users' memory results in a trap to the OS, which treats the attempt as a fatal error
- Only the OS can use privileged instruction to load the basic and limit registers
- We need to make sure that each process has a separate memory space.
Two registers are used to limit the range of the process memory
- Address binding
- A program needs to be loaded into memory to be executed, the process of converting symbolic addresses in the source program into relocatable physical addresses is called address binding
- A user program goes through several steps, some of which may be
optional, before being executed.
- A compiler binds symbolic addresses in the source program to relocatable addresses
- The linker or loader binds the relocatable addresses to absolute addresses
- The binding of instructions and data to memory addresses can be done
at any step
- Compile time: if you know at compile time where the process will reside in memory, then absolute code can be used. If, in later time, the address changes, then it will be necessary to recompile the program
- Load time: If it's not know at compile time where the process will reside in memory, the the compiler must generate relocatable addresses. Final binding is delayed until load time. If the address changes, we need only reload the code
- Execution time: if the process can be moved during execution from one memory segment to another, then the binding must be delayed until run time. Special hardware must be available for this scheme to work. Most operating systems use this method
- Logical and physical address space
- An address generated by the CPU is commonly referred to as a logical address, an address seen by the memory unit (the one that is loaded into the memory address register of the memory), is commonly referred to as a physical address
- Binding at compile time or load time results in identical logical and physical addresses. Binding at execution time results in differing logical and physical addresses
- Logical address space: the set of logical addresses. Physical address space: the set of physical addresses
- The user program can never access the real physical addresses, it
deals with logical addresses only. The mapping of logical address to
physical address is done by the memory mapping hardware, this is only
used in run time binding
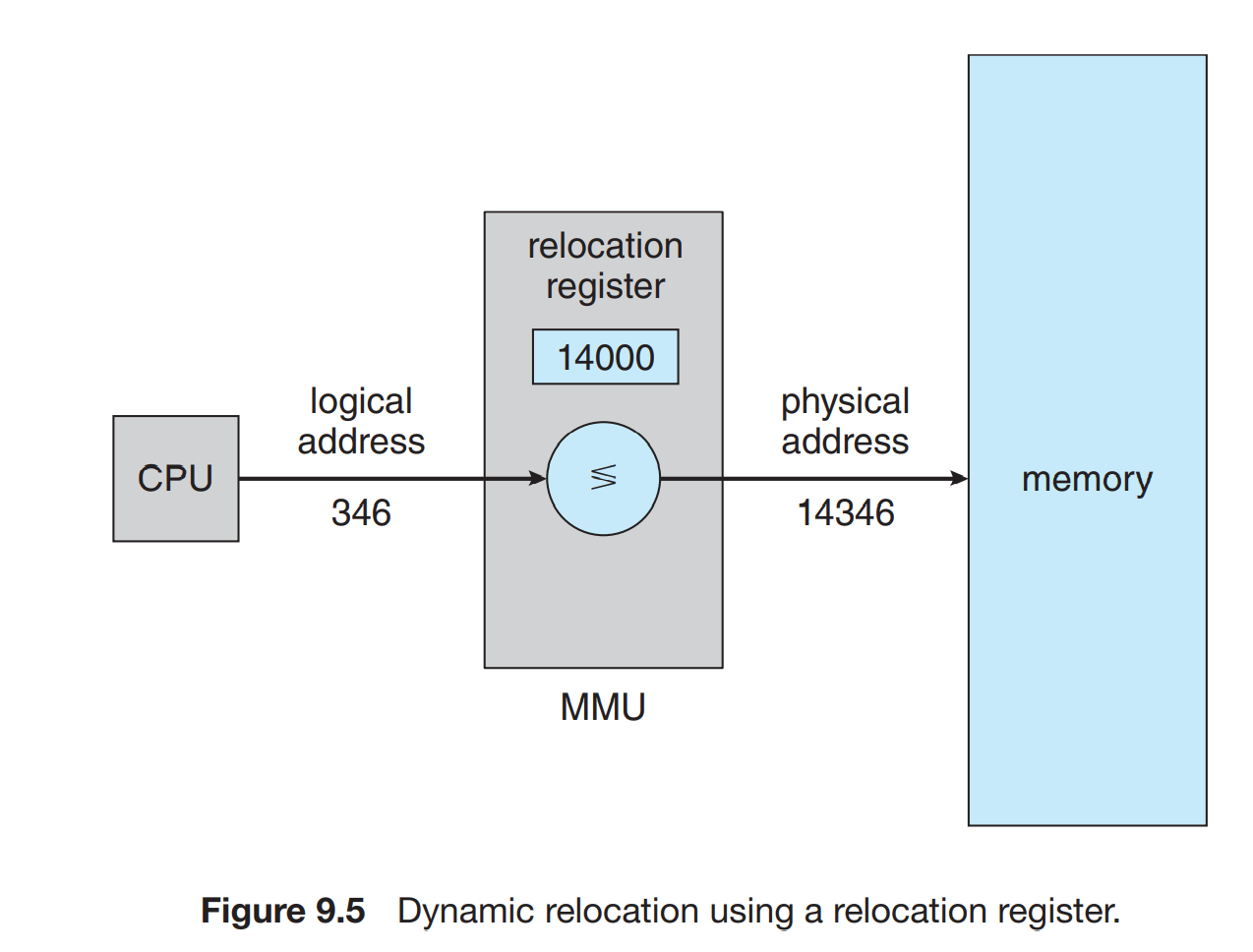
- Dynamic loading
- The entire program does not need to be loaded into the memory
- To achieve better memory-space utilization, we can use dynamic loading, a routine is not loaded until it is called. All routines are kept on disk in a relocatable load format
- The advantage of dynamic loading is that a routine is loaded only when it is needed
- Dynamic loading does not require special support from the OS
- Dynamic linking and shared libraries
- Dynamically linked libraries(DLLs, aka shared libraries) are system libraries that are linked to user programs when the programs are run
- Dynamic linking requires help from the OS
- Contiguous memory allocation Ch 9.2
- The main memory must accommodate both the operating system and the various user processes. Many OSs (including Linux and Windows) place the OS in high memory
- In contiguous memory allocation, each process is contained in a single section of memory that is contiguous to the section containing the next process
- Memory protection
- Use base register (relocation register) and limit register to specify the range of a process
- During context switch, the correct values of the relocation register and limit register are loaded into the CPU
- Memory allocation
- A simple approach
- Assign processes to variably sized partition in memory, each partition contains one process, the OS keeps a table indicating which parts of memory are available and which are occupied
- If there is no available space, the OS can either provide an error message, or put the process into a waiting queue
- Dynamic storage allocation problem
- Problems: how to satisfy a request of size n from a list of free holes
- First-fit: allocate the first hold that is big enough, search can start from either the beginning or the location where previous first-fit search ended
- Best-fit: allocate the smallest hold that is big enough, must search the entire list
- Worst-fit: allocate the largest hole, must search the entire list
- There is no clear advantage in terms of storage utilization, but generally first fit is faster
- A simple approach
- Fragmentation
- As processes are loaded and removed from memory, the free memory space is broken into little pieces
- External fragmentation
- Definition: there is enough total memory space to satisfy a request but the available space are not contiguous
- Solution 1 to external fragmentation: compaction, so all free memory is placed together in one large block
- Solution 2 to external fragmentation: allow the logical address space to be noncontiguous, thus allowing a process to be allocated physical memory wherever such memory is available
- 50-percent rule: given N allocated blocks, another 0.5N will be lost to fragmentation, that is, one-third of memory may be unusable
- Internal fragmentation
- If there is a hole of size n, and a process request a hole of size m (m < n), the the cost to track n - m (especially when n - m << n) is very high
- We break the physical memory into fixed-size blocks, and each block is assigned to a process
- Internal fragmentation: the difference between the size of the block and the size of a process
- Paging Ch 9.3
- Paging is a memory management scheme that permits a process's physical address space to be noncontiguous
- Paging avoids external fragmentation and is used in most OS
- Basic method
- Frames and pages
- Frames are fixed-sized blocks in physical memory
- Pages are fixed-sized blocks in logical memory, a page has the same size as a frame
- During execution, the pages of a process are loaded into available memory frames
- Every address generated by the CPU is divided into two parts: a page
number (p) and a page offset (d)
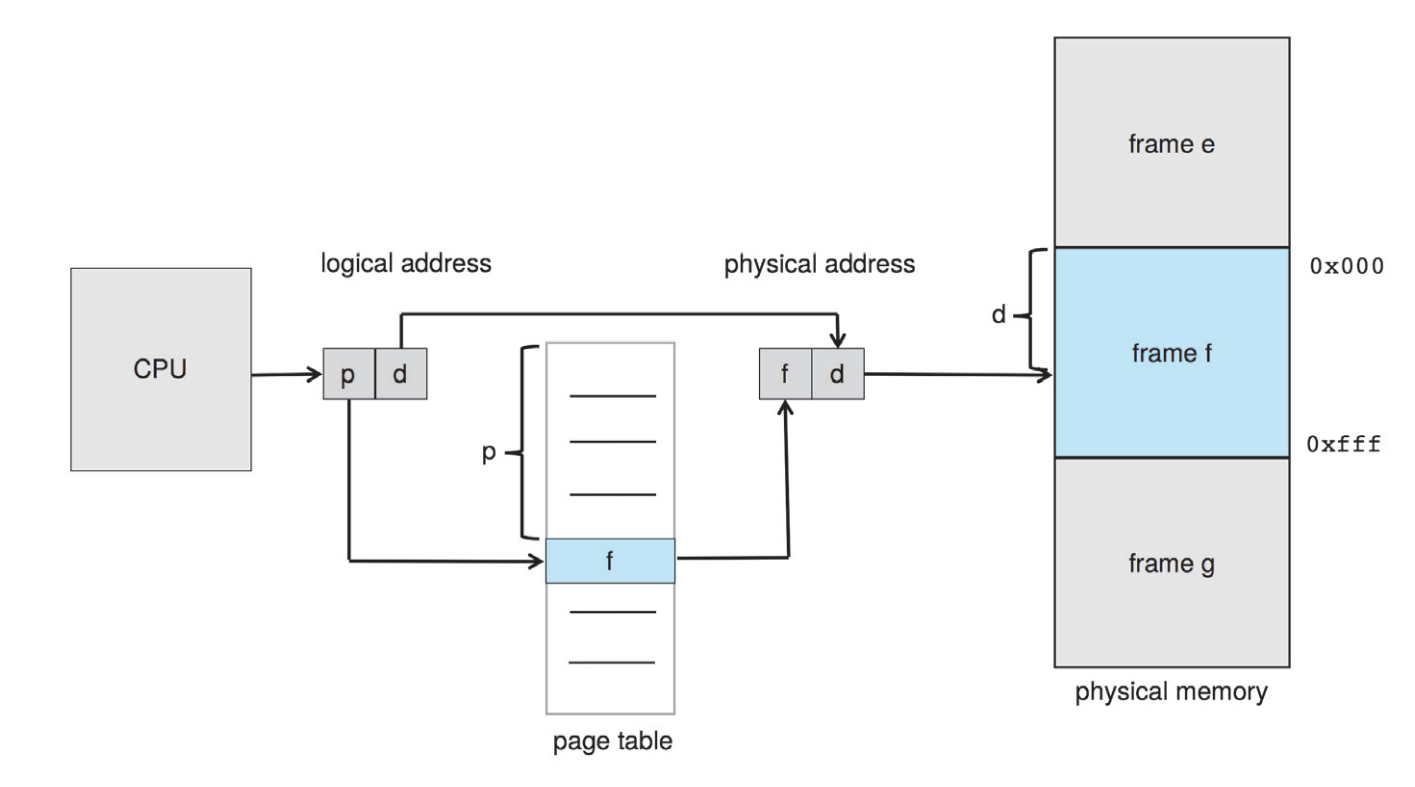
- Each process has a page table, which contains mapping from page number to base address of each frame in physical memory
- MMU address translation procedure
- Extract the page number p and use it as an index into the page table
- Extract the corresponding frame number f from the page table
- Replace the page number p in the logical address with the frame number f
- The offset d does not change, so it is not replaced
- With paging, we have no external fragmentation, but we can have internal fragmentation
- Size of a page
- If process size is independent of page size, then on average the size of internal fragmentation is one-half page size per process (For a page of size n, waste can be in [0, n -1] with equal probability, then on average is n /2)
- Logically, smaller page size is desirable. But overhead is involved in each page table entry, and this overhead is reduced as the size of the pages increases. Also, disk I/O is more efficient when the amount of data being transferred is larger
- Typical page size is 4KB or 8KB, some OSs support larger pages
- Frame table: the OS need to maintain the information about which frames are available and which frames are occupied, this information is in the frame table. The frame table is a single, system-wide data structure
- Frames and pages
- Hardware support
- Each process has its own page table, a pointer to the page table is stored in the PCB of each process. During context switch, the page table should be loaded into CPU
- Hardware implementation of page table
- Simplest approach: page table is implemented as a set of high-speed hardware registers, which makes the page-address translation very efficient. This increases the context switch time
- When the page table is large, it is kept in the main memory, and a page-table base register(PTBR) points to the page table. Changing page tables requires changing only this register during context switch time
- TLB
- Storing page table in main memory can yield faster context switch time, but it also results in slower memory access time (use p + PTBR to find f, then use f + d to find the physical address). So we use TLB to speed up
- Translation look-aside buffer(TLB) is a special, small, fast-lookup hardware cache. It contains a few page table entries
- Use TLB with page table
- When CPU generate the logical address, MMU searches in the TLB first
- If the page number is in the TLB, the frame number is immediately available
- If the page number is not in the TLB (called TLB miss), the MMU then searches the page table. When search in the page table is done, the entry is added to the TLB
- If the TLB is full, an existing entry is replaced with the latest one. Replacement policy can use LRU, round-robin, or random
- Some TLB stores ASIDs (address-space identifier) in each TLB entry. An ASID can uniquely identifies each process and is used to provide address-space protection for that process
- Hit ratio: the percentage of times that the page number of interest is found in the TLB
- Effective access time = hit ratio * access time in TLB + (1 - hit ration) * (access time in page table + access time in main memory)
- Protection
- Memory protection in a paged environment is accomplished by protection bits associated with each frame. Normally, theses bits are kept in the page table
- One additional bit is generally attached to each entry in the page table: a valid-invalid bit. This bit is valid if the page is in the process's logical address space
- Shared pages
- When part of the code of a process is reentrant code, then it can be shared
- Shared code has the same physical address then thus the same frame
- Structure of the page table Ch 9.4
- Most common techniques for structuring the page table: hierarchical paging, hashed page tables, inverted page tables
- Hierarchical paging
- Page table is paged to become smaller ones
- Two-level paging algorithm
- Logical address = page number for outer page table
- Because address translation works from the outer page table inward, this scheme is aka a forward-mapped page table
- Logical address = page number for outer page table
- If the paged table is still too large, the table can be further paged, so we can have a three-level page table...
- Hashed page table
- If the address space is larger than 32 bits, then we can use hashed page table.
- Hash with chaining collision resolution is used, key is the hash value of logical address, value is a linked list of objects. Each object contains the logical page number and value of the mapped page frame.
- One variation of hashed page table is clustered page table, where each object contains multiple physical page frames
- Inverted page tables
- An inverted page table has one entry for each real page of memory. Each entry consists of the virtual address of the page stored in that real memory location, with information about the process that owns the page.
- Only one page table is needed in the system, and it has only one entry for each page of physical memory
- This approach decreases the amount of memory needed to store each page table, it increases the amount of time needed to search the page table when a page reference occurs
- This approach also cannot use shared memory: in the standard page table with shared memory, multiple logical addresses map to the same physical address, but in the inverted page table, one physical address cannot be mapped to multiple logical addresses
- Swapping Ch 9.5
- Process instructions and the data they operate on must be in memory to be executed. However, a process, or a portion of a process, can be swapped temporarily out of memory to a backing store and then brought back into memory for continued execution
- Swapping makes it possible for the total physical address space of all processes to exceed the real physical memory of the system, thus increasing the degree of multiprogramming in a system
- Standard swapping
- Move entire processes between main memory and a backing store, the backing store is commonly fast secondary storage
- It allows physical memory to be oversubscribed, so that the system can accommodate more processes thant there is actual physical memory to store them
- Swapping with paging
- Standard swapping is generally no longer used in contemporary OSs, because the amount of time required to move entire processes is prohibitive
- Most OSs use a variation of swapping in which pages of a process can be swapped
- Generally, swapping refers to standard swapping, paging refers to swapping with paging
- Page out moves a page from memory to the backing store, page in is the reverse operation
- Swapping on mobile systems
- Mobile systems typically do not support swapping in any form
- Reasons for not support swapping
- Mobile devices generally use flash memory rather than more spacious hard disk for nonvolatile storage
- Flash memory limits the number writes it can tolerate before it becomes unreliable
- The throughput between main memory and flash memory is also limited
- When free memory falls below a certain threshold, IOS asks applications to voluntarily relinquish allocated memory
- Android may terminate a process if insufficient free memory is available
- Example: Intel 32- and 64-bit architecture
- IA-32 architecture
- Memory management in IA-32 systems is divided into two components:
segmentation and paging

- IA-32 segmentation
- IA-32 allows a segment to be as large as 4 GB, and the maximum number of segments per process is 16K
- The logical address space of a process is divided into two
partitions
- The first partition is up to 8K segments that are private to the process. Information about the first partition is kept in the local descriptor table (LDT)
- The second partition is up to 8K segments that are shared among all processes. Information about the second partition is kept in the global descriptor table (GDT)
- Each entry in the LDT and GDT contains an 8-byte segment descriptor with detailed information about a particular segment, including the base location and limit of that segment
- The logical address is a pair (selector, offset)
- The selector is a 16-bit number, the first 13 bits designate the segment number s, the 14th bit indicates whether the segment is in LDT/GDT, and the last 2 bits deal with protection
- The offset is a 32-bit number specifying the offset within the segment
- The machine has 6 segment registers, allowing 6 segments to be addressed at any one time by a process
- The linear address is 32 bits long, it is the just the offset in the logical address plus the base address of the segment (acquired from a specific entry in LDT/GDT)
- IA-32 paging
- The IA-32 allows a page size of either 4KB or 4MB
- For 4KB pages, IA-32 uses a two-level paging scheme: for the 32-bit linear address, outer page number uses 10 bits, inner page number uses 10 bits, offset uses 12 bits
- For 4MB pages: for the 32-bit linear address, page number uses 10 bits, offset uses 22 bits
- Intel adopted a page address extension (PAE), which allows 32-bit processors to access a physical address space larger than 4GB. PAE uses a three-level paging scheme instead of a two-level paging scheme
- Memory management in IA-32 systems is divided into two components:
segmentation and paging
- X86-64 architecture
- Given the limitation of amount of bits in physical memory, the x86-64 architecture currently uses a 48-bit logical address with support for page sizes of 4KB, 2MB, or 1GB using four levels of paging hierarchy
- IA-32 architecture
- Background Ch 9.1
- Virtual memory
- Background Ch 10.1
- Virtual memory is a technique that allows the execution of processes that are not completely in memory
- Advantages
- Programs can be larger than physical memory
- Abstracts main memory into an extremely large, uniform array of storage, frees programmers from the concerns of memory-storage limitations
- Allows processes to share files and libraries, and to implement shared memory
- Provides an efficient mechanism for process creation
- Disadvantages
- Hard to implement
- May decrease performance if it is used carelessly
- Demand paging Ch 10.2
- How an executable program might be loaded from secondary storage
into memory
- Load the entire program in physical memory at program execution time
- Demand paging: load pages only as they are needed. Demand paging is commonly used in virtual memory systems
- Basic concepts
- Use valid-invalid bit scheme to distinguish between pages in memory
and pages in secondary storage
- Valid pages: pages that are in memory and inside the range of process address space
- Invalid pages: pages that are not in memory, or pages that are not inside the range of process address space
- Page fault: when a process tries to access a page that is not in memory (an invalid page). The paging hardware will notice the invalid bit and cause a trap to the OS.
- Procedures to handle page fault
- Check an internal table for the process to determine whether the address is valid or not
- If the reference was invalid, terminate the process. If the reference was valid but the page was not in memory, we now page it in
- Find an available frame, read the secondary storage to load the page into the newly allocated frame
- When the read operation is done, modify the internal table to indicate the page is not in memory
- Restart the instruction that was interrupted by the page fault trap
- The hardware to support demand paging is page table and secondary memory
- Use valid-invalid bit scheme to distinguish between pages in memory
and pages in secondary storage
- Free frame list
- When a page fault occurs, the operating system must bring the desired page from secondary storage into main memory. To resolve page faults, most operating systems maintain a free-frame list, a pool of free frames for satisfying such requests
- OS typically allocate free frames using a technique known as zero-fill-on-demand: previous contents of a frame are eliminated before being allocated
- Performance of demand paging
- Demand paging can significantly affect the performance of a computer system
- Effective access time with demand paging: EAT = (1 - page fault prob) * memory access time + p * page fault time
- Typically, page fault time = time to service the page fault interrupt + time to read the page into memory + time to restart the process
- Generally, EAT
- How an executable program might be loaded from secondary storage
into memory
- Copy on write Ch 10.3
- Process creation with
fork()system call can be achieved efficiently with copy-on-write - Traditionally,
fork()copies the parent's address space for the child, duplicating the page belonging to the parent - Copy-on-write: allow the parent and child process initially to share the same pages, the shared pages are marked as copy-on-write pages, if either process writes to a shared page, a copy of the shared page is created, modification will be on the copied page
- Several versions of UNIX provide a variation of the
fork()system call,vfork()(for virtual memory fork), that uses copy-on-write
- Process creation with
- Page replacement Ch 10.4
- If a page fault occurs but there is not available free frame to load
the page, there are several choices
- Choice 1: terminate the process
- Choice 2: use standard swapping and swap out a process, freeze all its frames and reduce the level of multiprogramming
- Choice 3: page replacement
- Basic page replacement
- Find a frame that is not currently being used and free it
- How to free a frame
- Write the contents of the frame to secondary storage
- Modify the page table to indicate the page is no longer in memory
- This approach involves two page transfers: page out one replaced page and page in the target page
- Use modify bit (dirty bit) to speed page replacement
- If the page is written into at any time, the modify bit is set to true
- When we want to replace a page, we check the modify bit, if it is true, we know it's modified since the last time it was read from secondary storage, then we need to page it out to secondary storage. If the modify bit is false, we do not need to page it out, because it's the same as the one in secondary storage
- Page replacement is basic to demand paging, it completes the separation between logical memory and physical memory
- We must solve two major problems to implement demand paging
- Develop a frame-allocation algorithm: if we have multiple processes in memory, we must decide how many frames to allocate to each process
- Develop a page-replacement algorithm: when page replacement is required, we must select the frames that are to be replaced
- In terms of page replacement algorithm, we want the one with the lowest page-fault rate
- FIFO page replacement
- A FIFO replacement algorithm associates with each page the time when that page was brought into memory
- When a page must be replaced, the oldest page is chosen
- We don't have to record the timestamp with each page, we can simply use a FIFO queue to hold the pages in memory
- The FIFO page replacement algorithm is easy to understand and program. But it's performance is not always good
- Belady's anomaly: for some page replacement algorithms, the page fault rate may increase as the number of allocated frames increases
- Optimal page replacement
- Optimal page replacement algorithm is the one that has the lowest page fault rate of all algorithms and will never suffer from Belaydy's anomaly
- The optimal algorithm does exist and has been called OPT or MIN, it's simply this: replace the page that will not be used for the longest period of time
- The optimal page replacement algorithm is difficult to implement, because it requires future knowledge of the reference string. So it is used mainly for comparison studies
- LRU page replacement
- We can sue the recent past as an approximation of the near future then we can replace the page that has not been used for the longest period of time. This approach is the least recently used (LRU) algorithm
- LRU replacement associates with each page the time of that page's last use. We can think of this strategy as the optimal page replacement algorithm looking backward in time, rather than forward
- The LRU policy is often used as a page replacement algorithm and is considered to be good
- LRU implementation
- Approach 1: each page table entry has a timestamp and there is a clock/counter in the CPU. The clock is incremented each time a page is referenced. When a page is referenced, the value of the clock is copied to the timestamp field of its page table entry. When we want to replace a page, we replace the one with the smallest timestamp
- Approach 2: a hash map to contain pages that are in the memory and a doubly linked list to keep track of the order of pages (use a doubly linked list to mimic a stack, the LRU page is always at the bottom of the stack)
- LRU page replacement does not suffer from Belady's anomaly, it belongs to a class of page replacement algorithms, called stack algorithms, that can never exhibit Belady's anomaly
- Both implementations of LRU need hardware assistance
- LRU approximation page replacement
- If the hardware does not provide sufficient support, then we cannot use LRu page replacement. If there is a reference bit in each page table entry, then we can use the LRU approximation page replacement algorithm
- Reference bit
- Initially, all bits are set to 0 by the OS
- When a page is referenced (read or write), the bit is set to 1
- We do not know the order ot use
- Additional reference bits algorithm
- Gain additional ordering information by recording the reference bits at regular intervals
- Keep 8 bits to represent the history of usage of the page
- Each bit corresponds to one time interval, with the leftmost bit indicating the most recent time interval and the right most bit indicating the earliest time interval
- Shift bits to one right position at the end of each time interval
- Clock ticks determine intervals
- Convert the bits into unsigned integer, the page with the lowest value is replaced
- Second chance algorithm/clock algorithm
- The basic algorithm of second change replacement is a FIFO replacement algorithm
- Idea
- Check the reference bit if a page is selected
- If the reference bit is 0, replace this page
- If the reference bit is 1, we give it a second chance: reset the reference bit to 0 and move to the next FIFO page (this page will not be replaced until all other pages are checked)
- Implementation: a circular queue
- Counting based page replacement
- Least frequently used (LFU) page replacement algorithm: the page with the smallest count be replaced
- The most frequently used(MFU) page replacement algorithm
- Page buffering algorithms
- Used in addition to specific page replacement algorithm.
- OS maintains a pool of free frames. When a page fault occurs, before a page is written out, the desired page is read into a free frame in the pool, so the process can restart as soon as possible, without waiting for the victim page to be written out. When the victim is later written out, its frame is added to the free frame pool
- If a page fault occurs but there is not available free frame to load
the page, there are several choices